
Go 1.24 的 Swiss Map:兼容性、扩展哈希与遗留问题
在 上一篇文章中,我介绍了swiss map以及Dolthub 实现的一个Go语言版本。对于 swiss map 不太熟悉的读者,可以先去看看那篇文章。
在即将正式发布的Go1.24中swiss map 将作为现有map的替代者正式进入gosrc。它完全兼容现有API,并且在部分benchmark场景下带来了超过50%的性能提升。到目前为止,swiss map是我对于Go1.24最期待的功能了。可是它真的有期待中的那么好嘛?本文将从兼容性、扩展哈希(Extendible Hashing) 的实现与优势,以及遗留问题三个方面,深入剖析这一新设计的核心逻辑。
兼容性:无痛迁移的底层支持
Go 的swiss map 设计目标之一是与旧版 map 兼容。通过条件编译标签和类型转换,实现在新旧版本间的无缝切换。例如,在 export_swiss_test.go 中,newTestMapType 函数直接通过类型转换将旧版 map 的元数据转换为 swiss map 的类型结构:
|
|
这种设计允许现有代码无需修改即可通过实验性标志启用 swiss map,同时保留了旧版哈希表的内存布局兼容性。当前gotip(go1.24-3f4164f5) 中GOEXPERIMENT=swissmap 编译选项已经默认打开,也就是默认使用的是swiss map。
如果您还是想用 原来的map可以使用 GOEXPERIMENT=noswissmap
SwissMap的数据结构
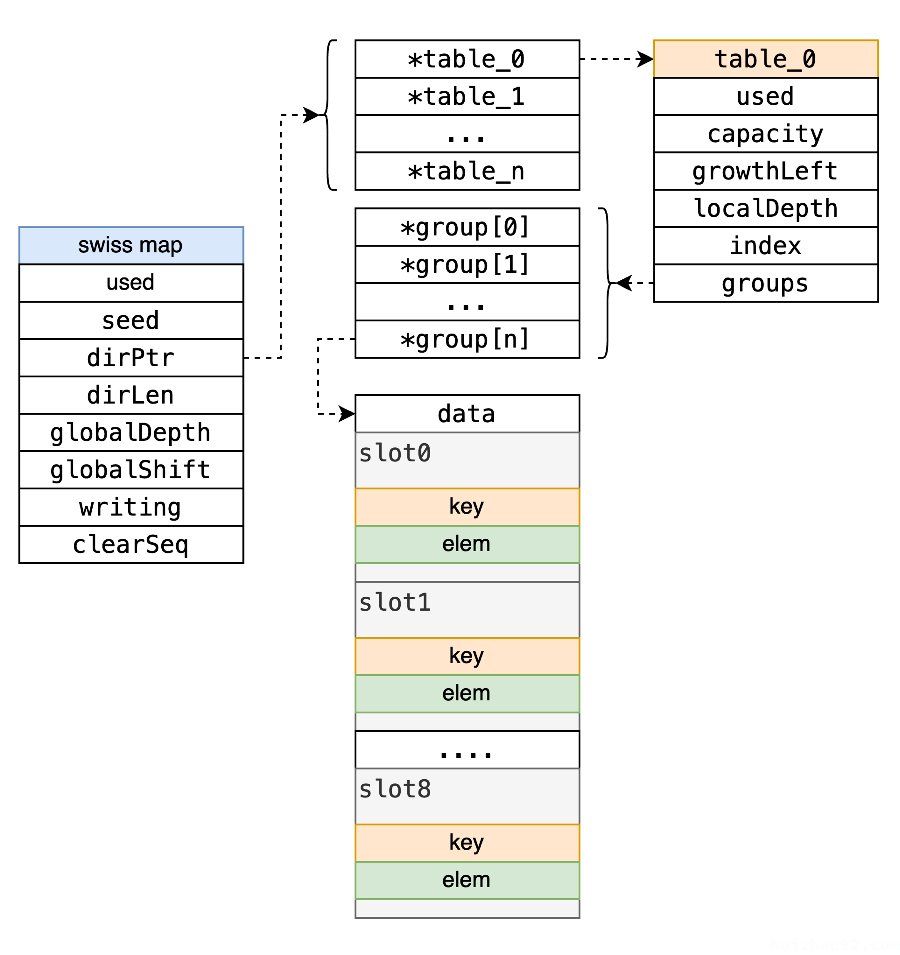
跟 Map 比较大的区别是
现在数据存储在Dir中,Dir 包含若干个table,同时每个table 有若干个group。
每个group有16个solt,solt就是最终的数据。并且现在数据排列方式跟以前不一样,不是key跟key在一起,value跟value在一起,而是混合在一起。
数据插入过程
// TODO
数据查询过程
查询使用的是线性探测。首先根据 hash key 以及 globalDepth 判断在那个table。
|
|
然后在根据高位key。
Extendible Hashing:如何实现动态扩展?
与其他其他几个社区实现,除了在兼容性方面的改进之外,swiss map的核心创新之一是采用了Extendible Hashing(扩展哈希),以支持高效的增量扩容。传统哈希表在扩容时需要全量迁移数据,而 ExtendibleHashing 通过多级目录和表拆分,将扩容开销分摊到多次操作中。
Dir与table的层级结构
在 map.go 的 Map 结构体中,globalDepth 和 directory 字段是关键:
|
|
dir大小为 1 << globalDepth,每个dir项指向一个 table。当某个 table 的负载过高时,会触发拆分(Split),而非全局扩容。
拆分操作
拆分(Split)是 swiss map在单个表容量达到 maxTableCapacity(默认为 1024)时触发的动态扩容机制。其核心目标是将一个表的负载分摊到两个新表中,避免全局扩容的高延迟。以下是拆分的关键步骤与地址变化:
拆分时,原表(假设为 table A)会创建两个子表 table Left 和 table Right。它们的localDepth(本地深度)比原表大 1,表示其哈希掩码多使用了一个高位比特。
|
|
left 和 right 是新分配的内存对象,其 groups.data 指向新分配的连续内存块(通过 newarray 函数)。
数据分配:哈希掩码与比特位判定
拆分时,根据哈希值的高位比特(由 localDepth 决定)将原表的数据分配到左表或右表。例如,若 localDepth 为 2,则使用哈希值的第2个高位比特(从最高位开始计数)作为分配依据。
|
|
- 掩码计算:
localDepthMask根据localDepth生成一个掩码,例如:localDepth=1→0x80000000(32 位系统)或0x8000000000000000(64 位系统)。- 该掩码用于提取哈希值的第
localDepth个高位比特。
3. 目录的更新与扩展
拆分完成后,需要更新全局目录(Map.directory),使原表的索引范围指向新的子表。如果原表的 localDepth 等于全局的 globalDepth,则目录需要扩展(翻倍)。
目录扩展示例
假设原表 table A 的 localDepth=1,globalDepth=1,目录大小为 2(1 << 1)。拆分后:
- 目录翻倍:
globalDepth增加到 2,目录大小变为4(1 << 2)。 - 索引重映射:原表的目录项(例如索引
0-1)被替换为指向left和right表。
|
|
- 地址变化:
- 原表
table A的dirPtr指向的目录项被更新为新表的地址。 - 例如,原目录项
[A, A]变为[Left, Right](扩展后目录为[Left, Right, Left, Right])。
- 原表
示例:拆分前后的地址与目录变化
初始状态
- 全局目录:
globalDepth=1,目录大小为 2,指向同一个表A。1 2directory[0] → A (localDepth=1) directory[1] → A (localDepth=1)
触发拆分
- 创建子表:
Left(localDepth=2)和Right(localDepth=2)。 - 目录扩展:
globalDepth增加到 2,目录大小变为 4。 - 更新目录项:
1 2 3 4directory[0] → Left // 哈希前缀 00 directory[1] → Left // 哈希前缀 01(原属于 A 的低半区) directory[2] → Right // 哈希前缀 10 directory[3] → Right // 哈希前缀 11(原属于 A 的高半区)
- 地址变化:
directory[0]和directory[1]的指针从A变为Left。directory[2]和directory[3]的指针从A变为Right。
拆分后的数据分布
假设原表 A 的哈希键分布如下:
- 哈希值高位为
00或01→ 分配到Left。 - 哈希值高位为
10或11→ 分配到Right。
通过掩码 localDepthMask(2)(例如 0x40000000),提取哈希值的第 2 个高位比特,决定数据归属。
关键设计优势
- 局部性:仅拆分负载高的表,其他表不受影响。
- 渐进式扩容:目录按需扩展,避免一次性全量迁移。
- 地址连续性:新表的
groups.data是连续内存块,利于缓存优化。
其他优化
此外,swiss map 针对一些特定场景也有优化,比如针对于少量元素(<=8)就直接使用一个group来存储数据,尽量降低 swiss map 在少量数据的时候的性能劣势。
遗留问题与挑战
尽管 swiss map 在设计与性能上迈出了一大步,但仍存在以下待优化点:
并发支持的局限性
当前实现通过 writing 标志检测并发写入,但缺乏细粒度锁:
|
|
这在多线程高并发场景下可能导致竞争条件。官方文档提到未来可能引入更复杂的同步机制,但目前仍需依赖外部锁。
内存碎片化
swiss map 的 group 结构(8 控制字节 + 8 键值槽)可能导致内存对齐浪费,尤其是键值类型较小时。例如,若键为 int32、值为 int8,每个槽位将浪费 3 字节。
迭代器复杂度
Iter 的实现(table.go)需处理目录扩展和表拆分,逻辑复杂:
|
|
在频繁扩容的场景下,迭代器的性能可能受到影响。
此外,在最新的代码中,遗留了很多TODO

我甚至都不知道如何总结这些TODO, 目前距离 Go 1.24 正式发布还有不到一个月的时间,不知道这些TODO会不会全部解决。
在社区中关于swiss map 的讨论也还有很多,主要集中在性能优化方面,可以想象未来 还会出现很多变动。

一切都要等到2月份正式发布。
性能测试
完整的测试代码:https://github.com/hxzhouh/gomapbench
go version devel go1.24-3f4164f5 Mon Jan 20 09:25:11 2025 -0800 darwin/arm64
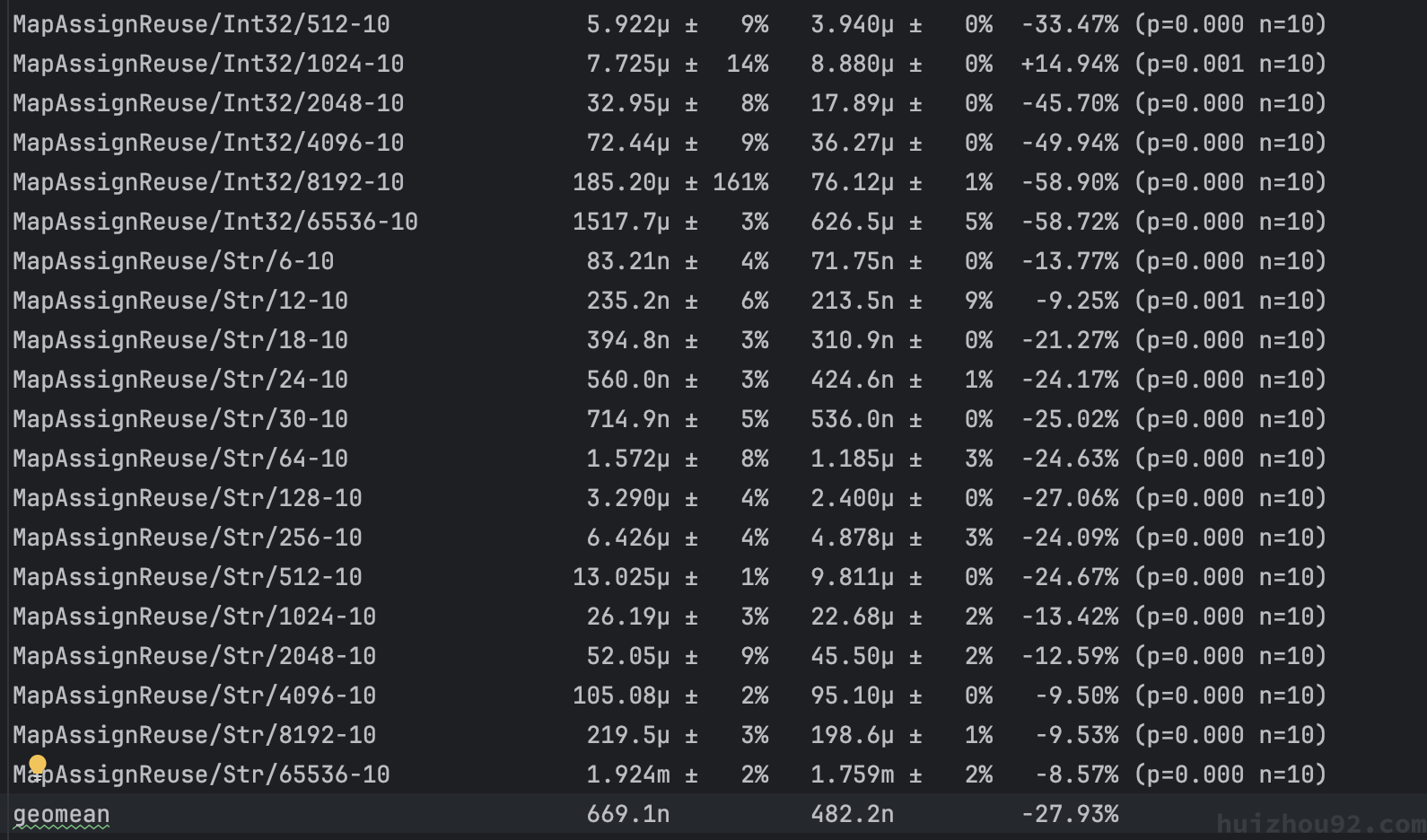
平均性能提升 28% 大约,在某些场景下,甚至高达 50%。不愧是Go1.24 最期待的功能。
但是,这是一份不严谨的性能测试,测试机器也仅限于我自己的笔记本电脑,有一些报告显示swiss map 在某些地方的性能甚至出现了下降。
https://x.com/valyala/status/1879988053076504761
https://x.com/zigo_101/status/1882311256541102178


最终swiss map 如何,还是要看后续的演化。
总结
Go 1.24 的 swiss map 通过兼容性设计、Extendible Hashing 和优化的探测序列,显著提升了哈希表在高负载场景下的性能。然而,其并发模型和内存效率仍有改进空间。对于开发者而言,这一新特性值得在性能敏感的场景中尝试,但也需关注其当前限制。
参考资料
https://tonybai.com/2024/11/14/go-map-use-swiss-table/
https://github.com/golang/go/issues/54766
https://pub.huizhou92.com/swisstable-a-high-performance-hash-table-implementation-3e13bfe8c79b
https://www.geeksforgeeks.org/extendible-hashing-dynamic-approach-to-dbms/