
问题:为什么你的 Agent 用久了反而「变笨」了?
想象一下这个场景:你和一个 AI Agent 协作了好几周,耐心地教它你的项目结构、个人偏好和工作流程。一次对话中,它确实记住了你的指令——但第二天开新会话,就像见了个陌生人。更糟的是,它开始自信满满地编造从未发生过的事情,反复问你同样的问题,把几小时前做出的关键决策忘得一干二净。
如果你也遇到过这种情况,别急着怀疑 Agent 的智力——这是记忆系统设计的根本缺陷。
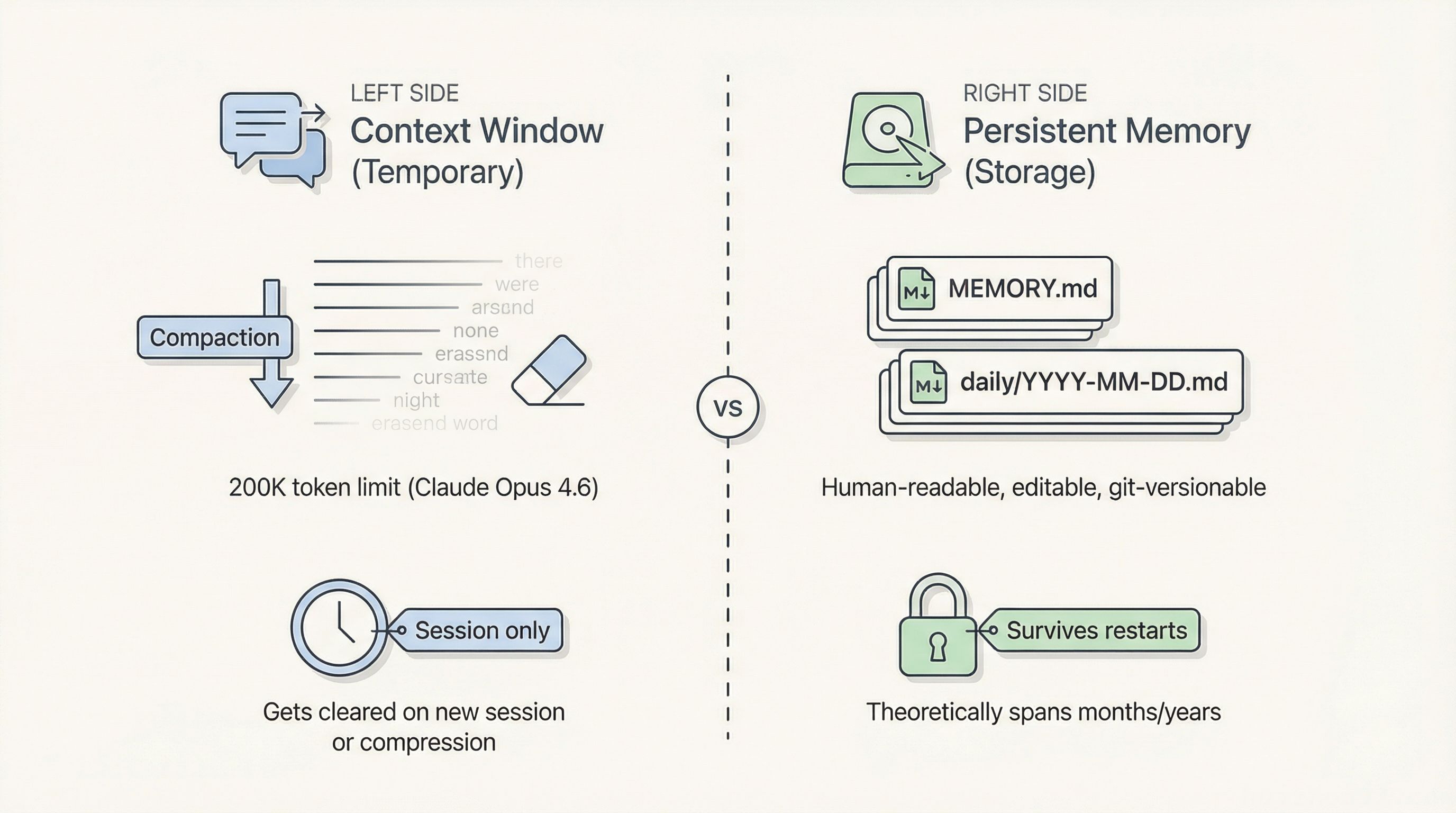
大多数人以为 AI「有记忆」,是因为它能回忆对话中的早期内容。但实际发生的事情简单得多:Agent 用的是它的 Context Window(上下文窗口),这只是一个临时工作区,不是永久存储。对话过长触发压缩、或者你开了一个新会话——工作区就被清空了。
OpenClaw 试图解决这个问题,做法是将长期记忆持久化到本地 Markdown 文件(MEMORY.md、每日日志等)。理论上,记忆可以跨越数月甚至数年;文件存在磁盘上,人类可读、可编辑、可 Git 版本控制——听起来很完美。
然而大量用户反馈:Agent 随着时间推移变得越来越"痴呆"。
根因可以归为三个层面:
-
压缩引发的"摘要失忆":当 Context Window 接近上限(比如 Claude Opus 4.6 的 200K token 边界),OpenClaw 会自动触发压缩——让模型把早期对话「摘要」成更短的版本,然后丢弃原始历史。关键细节就在这个翻译过程中丢失了。
-
检索失败——“记住了却想不起来”:重要信息确实写进了磁盘(
MEMORY.md、daily/YYYY-MM-DD.md),但需要的时候依赖memory_search/memory_get工具去检索。漏检的原因包括:底层 Embedding 模型能力不足、纯语义搜索漏掉了关键词匹配、MEMORY.md随时间膨胀变得臃肿不堪。 -
没有遗忘 + 没有冲突解决:OpenClaw 几乎从不遗忘——文件只增不减。过时的偏好、废弃的项目决策、早期的错误指令全部堆积在一起。新信息到来时系统不会「更新」,只是追加。矛盾不断积累,检索时噪声稀释了信号。最终 Agent 变得困惑,开始编故事来调和相互矛盾的"事实"。
当前记忆系统的六大结构性缺陷
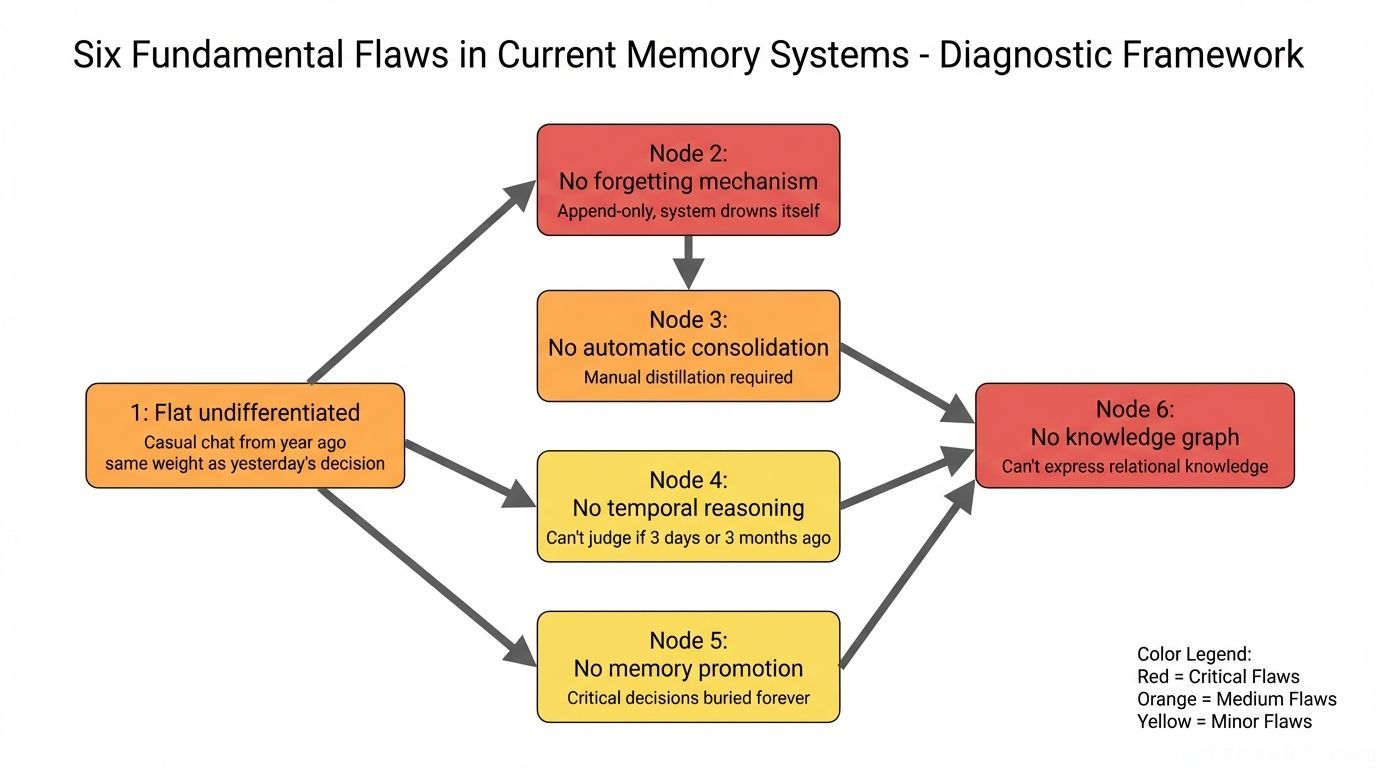
OpenClaw 的默认记忆方案——Markdown 文件 + 向量搜索——优势很明显:人类可读可写、可 Git 版本控制、零外部依赖。但我在实际使用中发现它有六个结构性弱点,而且每个都不是小问题:
1. 扁平无差异:一年前的闲聊和昨天的架构决策权重相同,搜索结果淹没在噪声中。
2. 没有遗忘机制:只追加不删除。记忆系统最终淹没自己——过时信息伪装成「事实」,污染当前决策。
3. 没有自动整合:重要洞察必须手动提炼和写入,Agent 永远不会主动「消化」今天发生了什么。
4. 没有时间推理:Agent 知道「某事发生过」,但不知道那是 3 天前还是 3 个月前——无法判断信息是否已经过时。
5. 没有记忆提升:埋在日志里的关键决策永远埋着,没有机制将它们提升到长期知识库。
6. 没有知识图谱:无法表达关系性知识,比如「A 认识 B」或「项目 X 依赖工具 Y」。所有记忆都是孤立的扁平条目。
学术界怎么说?(2026 年 2 月研究综述)
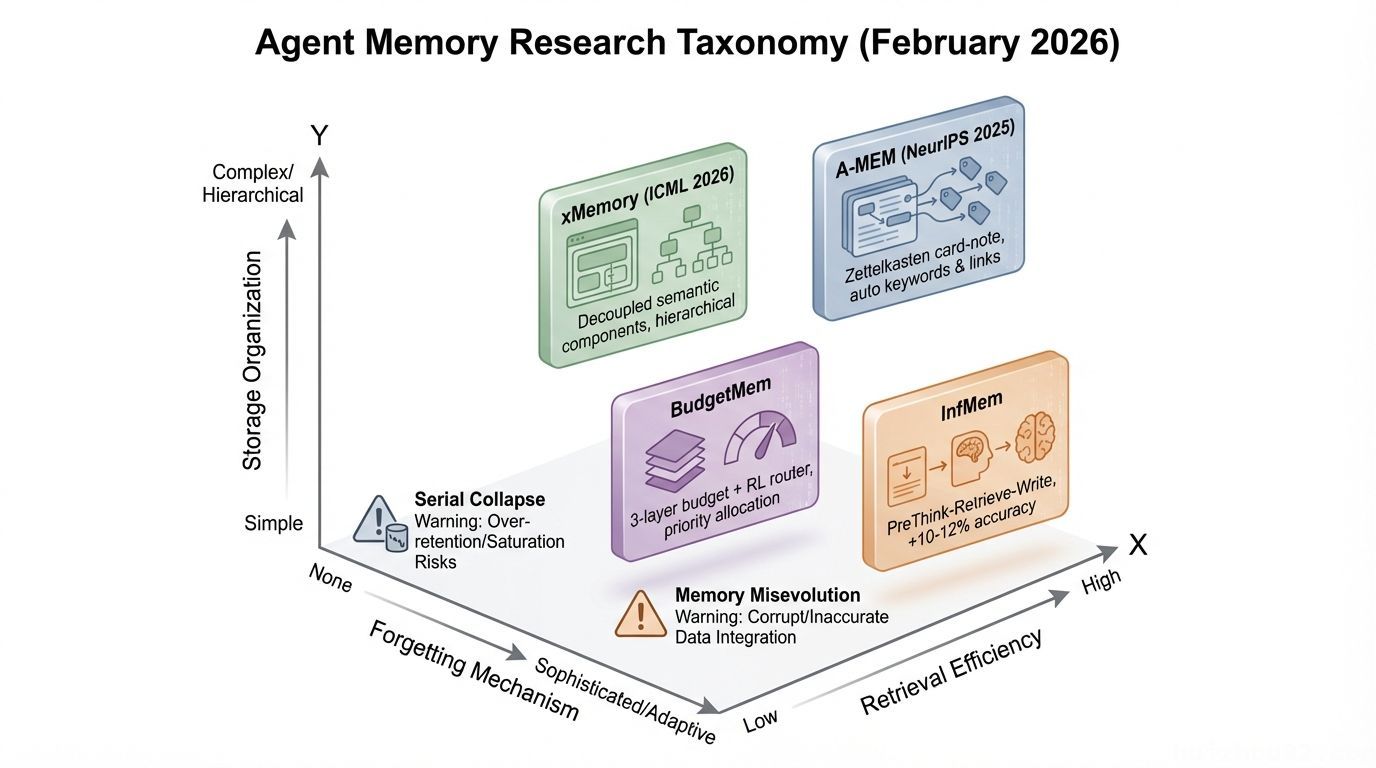
2026 年 2 月,Agent 记忆突然成了学术界的热门战场——单月发表了 10+ 篇论文。其中一篇由 59 位作者联合撰写的综述论文提出了三维分类法。
我挑几篇关键的说一下:
- A-MEM(NeurIPS 2025):借鉴了 Zettelkasten 卡片笔记法——新记忆自动生成关键词和关联链接,构建互联知识网络。思路很有意思。
- xMemory(ICML 2026):将记忆解耦为语义组件,层次化组织,支持自顶向下检索,大幅降低检索噪声。
- BudgetMem:三层预算结构 + RL Router,把检索资源优先分配给最重要的记忆。
- InfMem:PreThink-Retrieve-Write 协议,让 Agent 在检索前先「想清楚要找什么」,准确率提升 10-12%。
但更值得注意的是两个行业警告:
⚠️ Serial Collapse(序列崩溃)(Dark Side of the Moon 论文):Agent 可能逐渐退化到完全不使用记忆——即使记忆系统运行完好。记忆存在 ≠ Agent 会用。
⚠️ Memory Misevolution(记忆误进化)(TAME 论文):正常迭代过程中「有毒捷径」的积累——那些看起来高效但违反约束的记忆策略。
这两个警告在实践中其实很常见。你可能已经观察到了:Agent 有时候明明有记忆文件,却压根不去查。
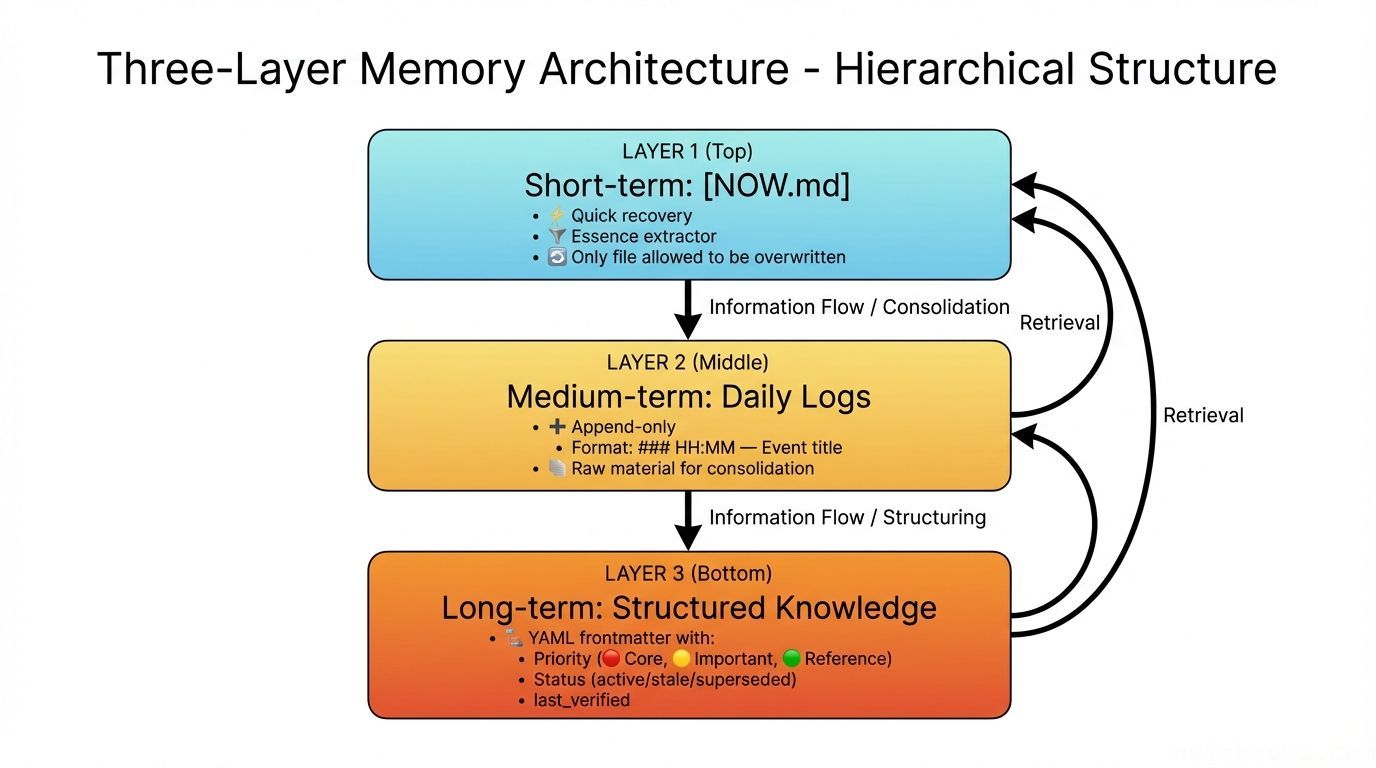
解决方案:三层记忆架构
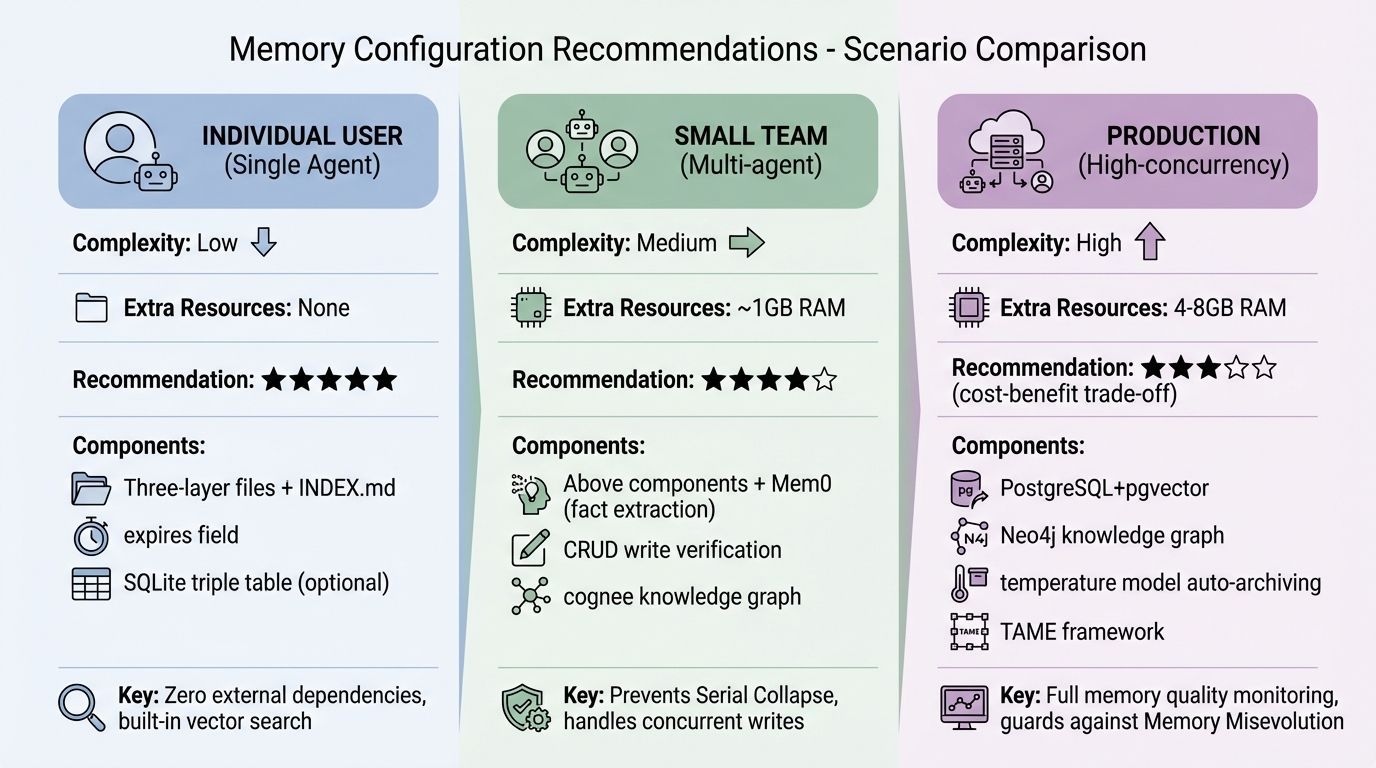
综合以上研究和我自己的实践,下面是一套面向个人用户的确定性零成本架构。
先贴一下我自己的记忆系统目录结构:
|
|
我们逐层来看。
短期层:NOW.md(最被忽视的设计)
NOW.md 是整个架构中信息密度最高的文件。
核心思想很简单:每次重启后,Agent 的第一个动作应该是读 NOW.md,而不是去搜索庞大的记忆库。它是精华提取器,是「我上次做到哪了」的快速恢复工具,是压缩后的救生筏。
|
|
关键规则:NOW.md 是唯一允许覆写的文件。所有其他记忆文件只能追加。
中期层:每日日志
- 文件名:
memory/YYYY-MM-DD.md - 写入模式:只追加,不覆写
- 格式建议:
### HH:MM — 事件标题 + 内容描述 - 原则:宁多勿少。日志是原材料,精华提炼交给夜间自动化。
长期层:结构化子目录
知识文件采用统一的 YAML frontmatter 格式:
|
|
last_verified 超过 30 天的条目自动标记为 ⚠️ stale,提醒人工复查。
INDEX.md:知识库健康仪表盘
|
|
Agent 启动时扫一眼 INDEX.md,几秒钟内就能了解整个知识库的健康状况。
轻量知识图谱:SQLite 三元组表
这是六大缺陷中最复杂的一个,也是纯 Markdown 无法突破的根本限制。
为什么需要知识图谱?
Markdown 文件只能存储扁平事实:
Brian 偏好简洁的沟通风格。项目 X 使用 PostgreSQL。工具 Y 需要 API Key。
但真实知识是有关系的:
Brian → 负责 → 项目 X → 依赖 → 工具 Y → 需要 → API Key(存放在 secrets/)
当 Agent 被问到「Brian 的项目需要什么 API Key」时,纯向量搜索无法完成这个三跳推理。
解决方案:一个 SQLite 三元组表。 没有外部依赖,没有部署开销,完全能满足个人知识关系管理的需要:
|
|
用 Python 或 Node 进行读写和查询就行。整个数据库就是一个 .db 文件,和你的 Markdown 记忆放在一起——可移植、备份极其简单。
什么时候该写入知识图谱
不是所有信息都值得入图。我的建议是只用于以下场景:
- 系统依赖:项目 A 依赖工具 B,工具 B 需要配置 C
- 资源位置:凭证 / 文件 / API 存放在哪里
- 历史关联:决策 X 的产生是因为事件 Y
日常事实(偏好、操作日志)留在 Markdown 里就好——别过度入图。

遗忘机制:主动遗忘比被动记忆更重要
这一点可能反直觉,但遗忘是记忆系统最关键的能力之一。
每条记忆用如下格式标注优先级和过期时间:
|
|
保留策略很简单:
|
|
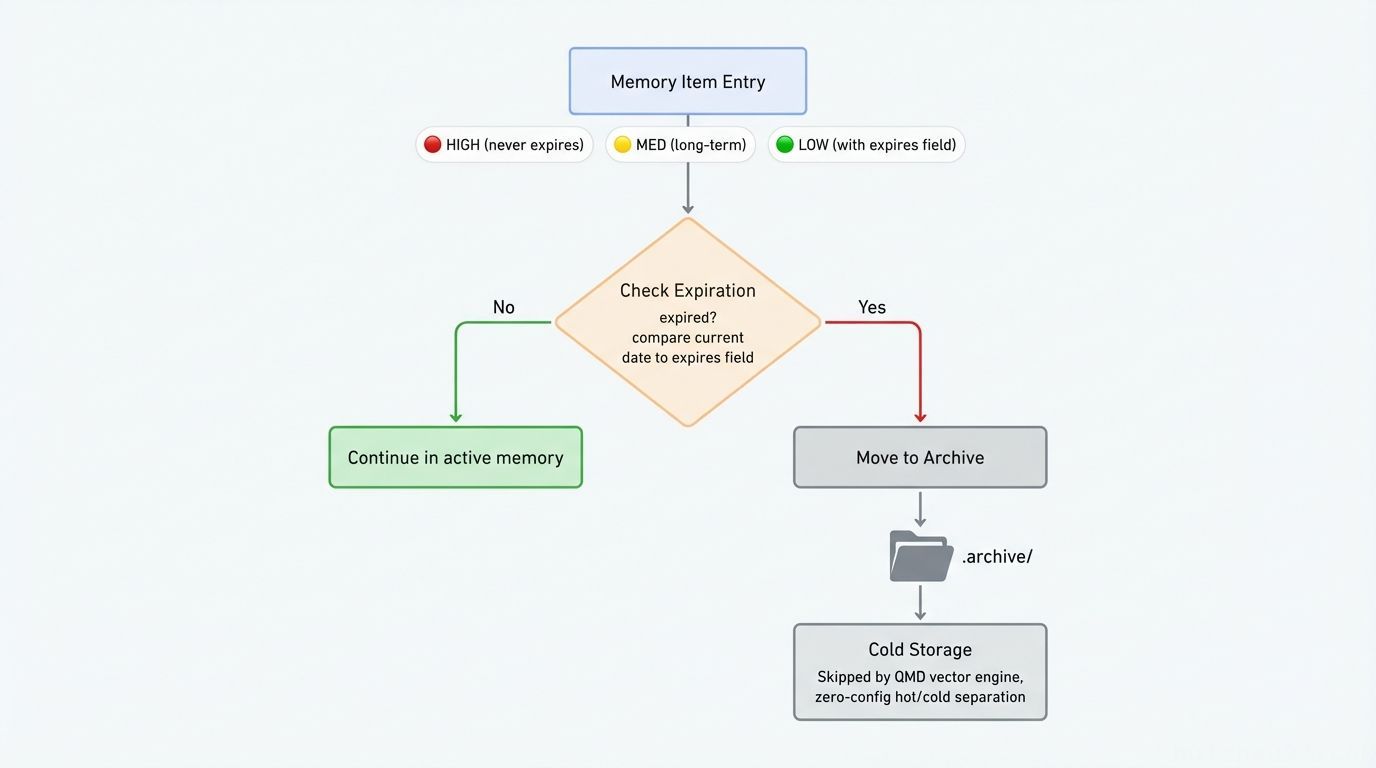
.archive/ 冷存储设计:用点号前缀命名目录。OpenClaw 的 QMD 向量引擎会自动跳过点号前缀的目录,实现零配置的热/冷索引分离。归档文件不会被删除——通过文件系统仍然可以直接访问。
一个简单的每周 cron 脚本负责清理:扫描过期的 expires: 字段,将对应条目移入 .archive/,同步更新 INDEX.md。
自动整合:让记忆系统学会「消化」
光有好的存储结构还不够——如果记忆不能自动整合,那它只是一个手动维护的文件夹。
时间标注是关键。每条记忆都必须包含时间关系标注,解决前面提到的「没有时间推理」问题:
- 「首次出现:……」
- 「继上次 X 之后,今天完成了 Y」
- 「首次讨论至今已 N 天,状态:已完成」
每晚自动整合(via cron):设置一个每晚执行的 cron 任务,调用你现有的 LLM API 来完成以下工作:
- 读取今天的每日日志(
memory/YYYY-MM-DD.md) - 提取关键决策、经验教训和状态变更
- 将重要条目提升到长期知识文件(带规范的 YAML frontmatter)
- 更新
NOW.md中明天的优先级 - 更新
INDEX.md健康仪表盘
这里有一个容易踩的坑:写入前必须先读取目标文件,对比是否已有类似内容,避免重复条目和记忆冲突(也就是 HaluMem 问题)。
搭建清单
以下是落地这套架构你需要的全部东西:
- 三层文件结构:
NOW.md+memory/YYYY-MM-DD.md+ 结构化子目录(lessons/、tools/等) INDEX.md:知识库健康仪表盘,启动时读取- 每晚 cron 任务:调用现有 LLM API 自动整合
expires字段 + 每周清理脚本:主动遗忘机制- 内置向量搜索:无需额外部署(OpenClaw 默认自带)
- SQLite 三元组表(可选):只在你确实有多跳关系推理需求时才加
不需要任何额外资源——一切都在你现有的设备上运行。
三个常见误区
在实践中我观察到不少人踩坑,这里总结三个最常见的:
误区一:记忆越多越好。 恰恰相反——过时的、低质量的记忆比没有记忆更危险。它们伪装成「事实」影响 Agent 的判断。遗忘机制和写入机制同样重要。
误区二:只写不读。 把信息写入记忆不代表 Agent 就会使用它。前面提到的 Serial Collapse(Agent 逐渐停止查询记忆)是真实存在的现象。定期验证 Agent 是否真的在用记忆,和构建记忆系统本身一样关键。
误区三:什么都往知识图谱里塞。 知识图谱的价值在于关系推理,不在于存储。日常偏好、操作日志放在 Markdown 里就够了——只有真正需要多跳推理的关系性知识才值得入图。
Summary
好的记忆系统不在于存得最多,而在于能在正确的时刻、以正确的形式、将正确的信息递给 Agent。
从三层架构(NOW.md + 每日日志 + 结构化长期文件)起步,加上每晚自动整合和简单的遗忘机制——对个人用户来说这就够了,除了你现有的 LLM API 之外零成本。只有当你确实需要多跳关系推理时,再加一个 SQLite 三元组表。
别把事情搞复杂了。上面这套架构解决了全部六个根本缺陷,而且一个下午就能搭好。
你也可以直接把本文复制给 OpenClaw,让它自动帮你搞定。