
The Problem: Why Does Your Agent Get Dumber Over Time?
Picture this: you’ve been working with an AI agent for weeks, patiently teaching it your project structure, personal preferences, and workflows. Within a single conversation, it remembers your instructions just fine — but the next day, when you start a new session, it’s like meeting a stranger. Worse still, it starts confidently fabricating events that never happened, asks you the same questions again, and forgets critical decisions made just hours ago.
If this sounds familiar, don’t blame the agent’s intelligence — the problem is a fundamental flaw in memory system design.
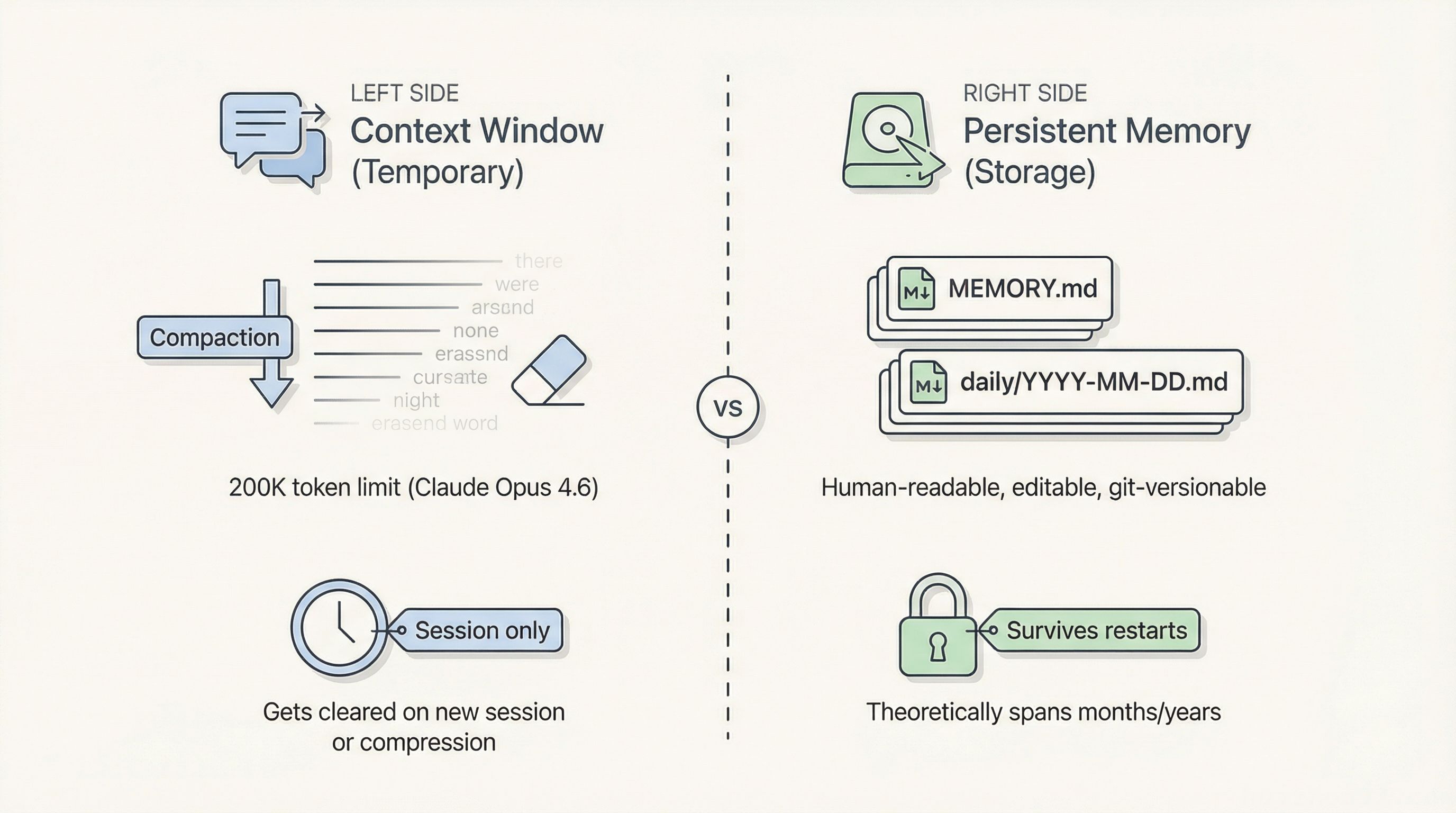
Most people assume AI “has memory” because it can recall earlier parts of a conversation. What’s actually happening is far simpler: the agent is using its Context Window — a temporary workspace, not permanent storage. When the conversation gets too long and triggers compaction, or when you start a new session, that workspace gets wiped clean.
OpenClaw tries to fix this by persisting long-term memory to local Markdown files (MEMORY.md, daily logs, etc.). In theory, memories can span months or even years. Files live on disk, are human-readable, editable, and git-versionable — sounds perfect, right?
Yet countless users report that their agents become progressively “demented” over time.
The root causes boil down to three layers:
-
Compaction-induced “summary amnesia”: When the Context Window approaches its ceiling (say, Claude Opus 4.6’s 200K token boundary), OpenClaw automatically triggers compaction — it asks the model to “summarize” earlier conversation into shorter chunks, then discards the originals. Critical details get lost in translation.
-
Retrieval failure — “remembered but can’t recall”: Important information does get written to disk (
MEMORY.md,daily/YYYY-MM-DD.md), but retrieval depends onmemory_search/memory_gettools. Missed recalls happen because the underlying embedding model isn’t strong enough, pure semantic search misses keyword matches, andMEMORY.mdbloats into an unwieldy mess over time. -
No forgetting + no conflict resolution: OpenClaw almost never forgets — files only grow, never shrink. Outdated preferences, abandoned project decisions, early incorrect instructions — they all pile up. When new information arrives, the system doesn’t “update”; it only appends. Contradictions accumulate, noise dilutes signal during retrieval. Eventually the agent gets confused and starts fabricating stories to reconcile conflicting “facts.”
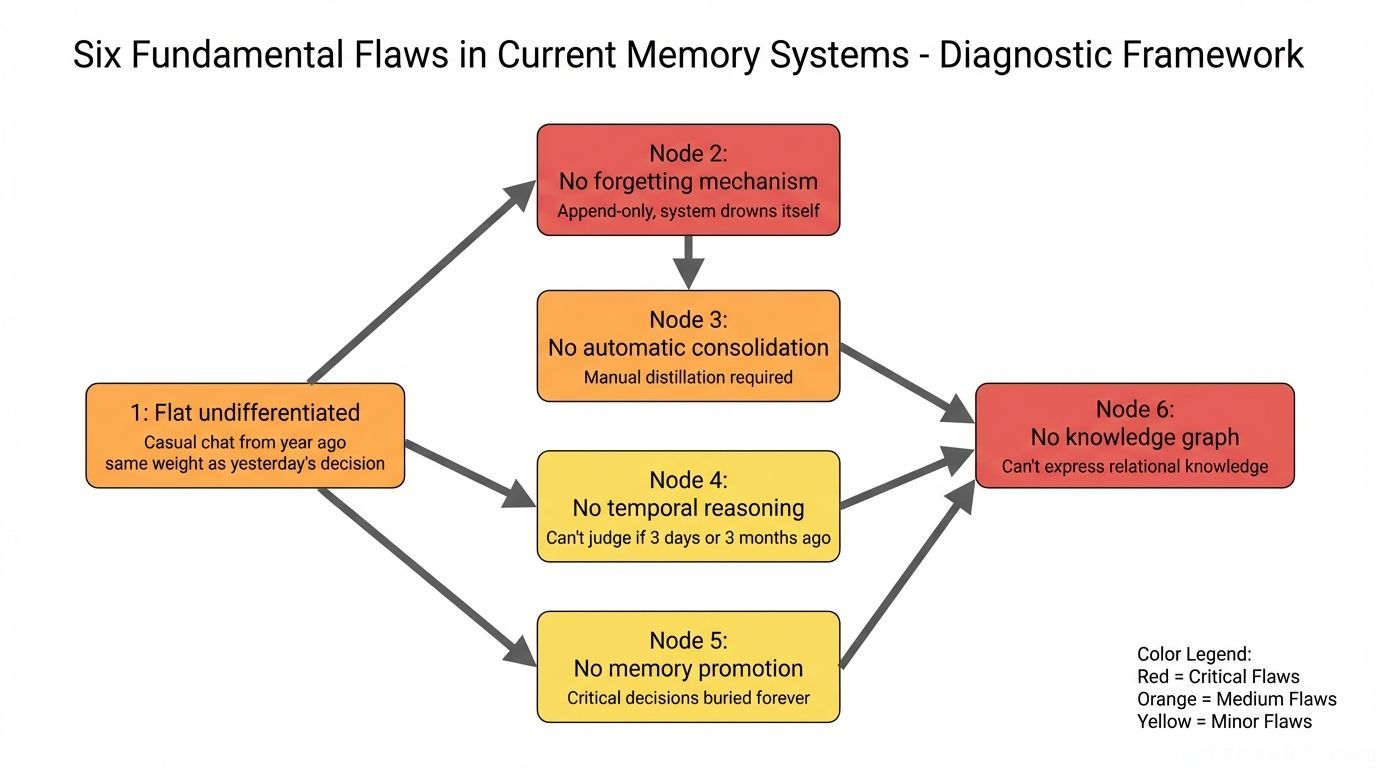
Six Structural Flaws in Current Memory Systems
OpenClaw’s default memory scheme — Markdown files + vector search — has obvious strengths: human-readable, git-versionable, zero external dependencies. But in practice, I’ve found six structural weaknesses, and none of them are trivial:
1. Flat and undifferentiated: A casual chat from a year ago carries the same weight as yesterday’s architecture decision. Search results drown in noise.
2. No forgetting mechanism: Append-only, never delete. The memory system eventually drowns itself — stale information masquerades as “facts” and pollutes current decisions.
3. No automatic consolidation: Important insights must be manually distilled and written in. The agent never proactively “digests” what happened today.
4. No temporal reasoning: The agent knows “something happened” but not whether it was 3 days or 3 months ago — it simply can’t judge whether information is stale.
5. No memory promotion: Critical decisions buried in logs stay buried forever. No mechanism promotes them to the long-term knowledge base.
6. No knowledge graph: Unable to express relational knowledge like “A knows B” or “Project X depends on tool Y.” Every memory is an isolated, flat entry.
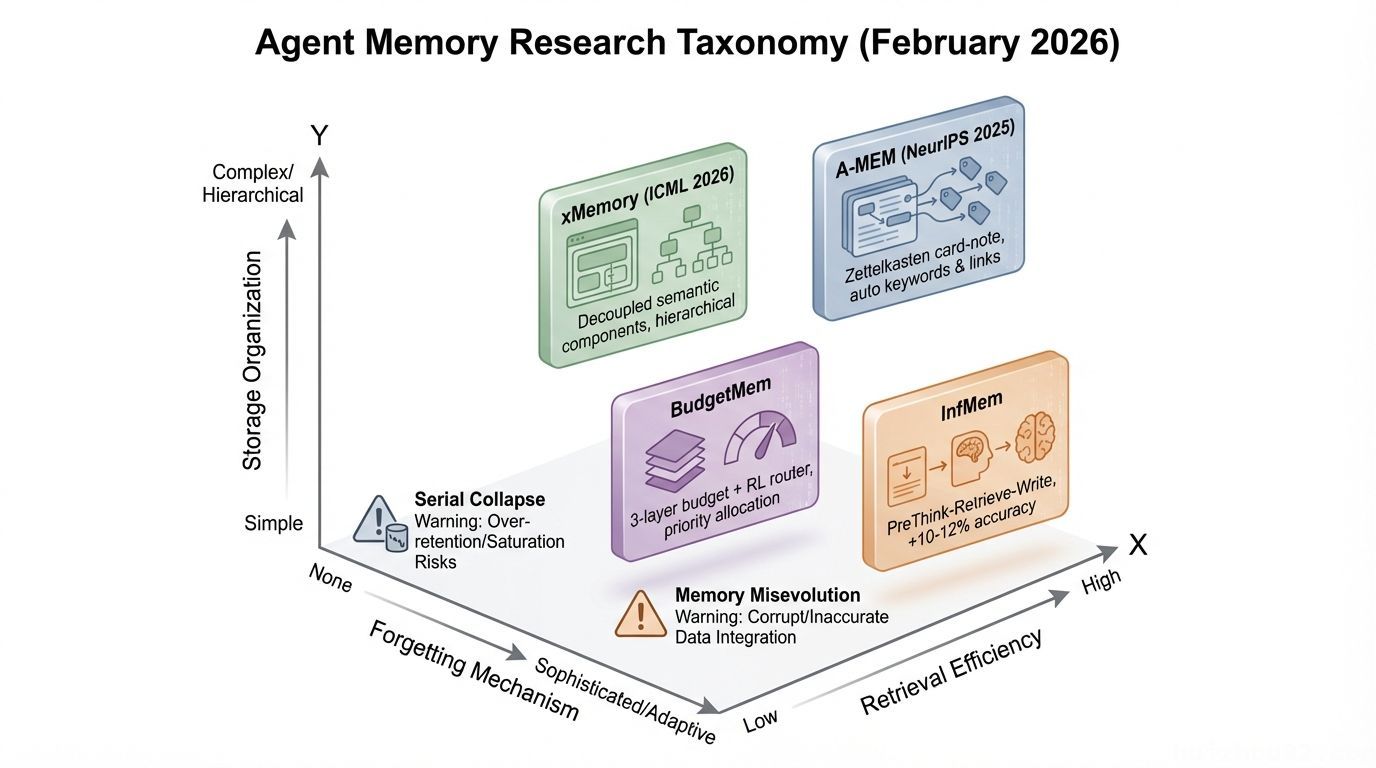
What Does Academia Say? (February 2026 Research Review)
In February 2026, agent memory suddenly became a hot academic battleground — 10+ papers published in a single month. One survey paper with 59 co-authors proposed a three-dimensional taxonomy for memory systems.
Let me highlight the key ones:
- A-MEM (NeurIPS 2025): Borrows from the Zettelkasten note-taking method — new memories auto-generate keywords and associative links, building an interconnected knowledge network. A fascinating approach.
- xMemory (ICML 2026): Decouples memory into semantic components, organizes them hierarchically, and supports top-down retrieval, dramatically reducing retrieval noise.
- BudgetMem: Three-layer budget structure + RL router that prioritizes retrieval resources for the most important memories.
- InfMem: PreThink-Retrieve-Write protocol — the agent “thinks about what to look for” before retrieval, boosting accuracy by 10–12%.
But what’s even more worth noting are two industry warnings:
⚠️ Serial Collapse (Dark Side of the Moon paper): Agents may gradually degenerate into not using memory at all — even when the memory system is running perfectly. Memory existing ≠ Agent using it.
⚠️ Memory Misevolution (TAME paper): Accumulation of “toxic shortcuts” during normal iteration — memory strategies that appear efficient but violate constraints.
These two warnings are extremely common in practice. You’ve probably noticed it yourself: sometimes the agent has memory files right there but simply never queries them.
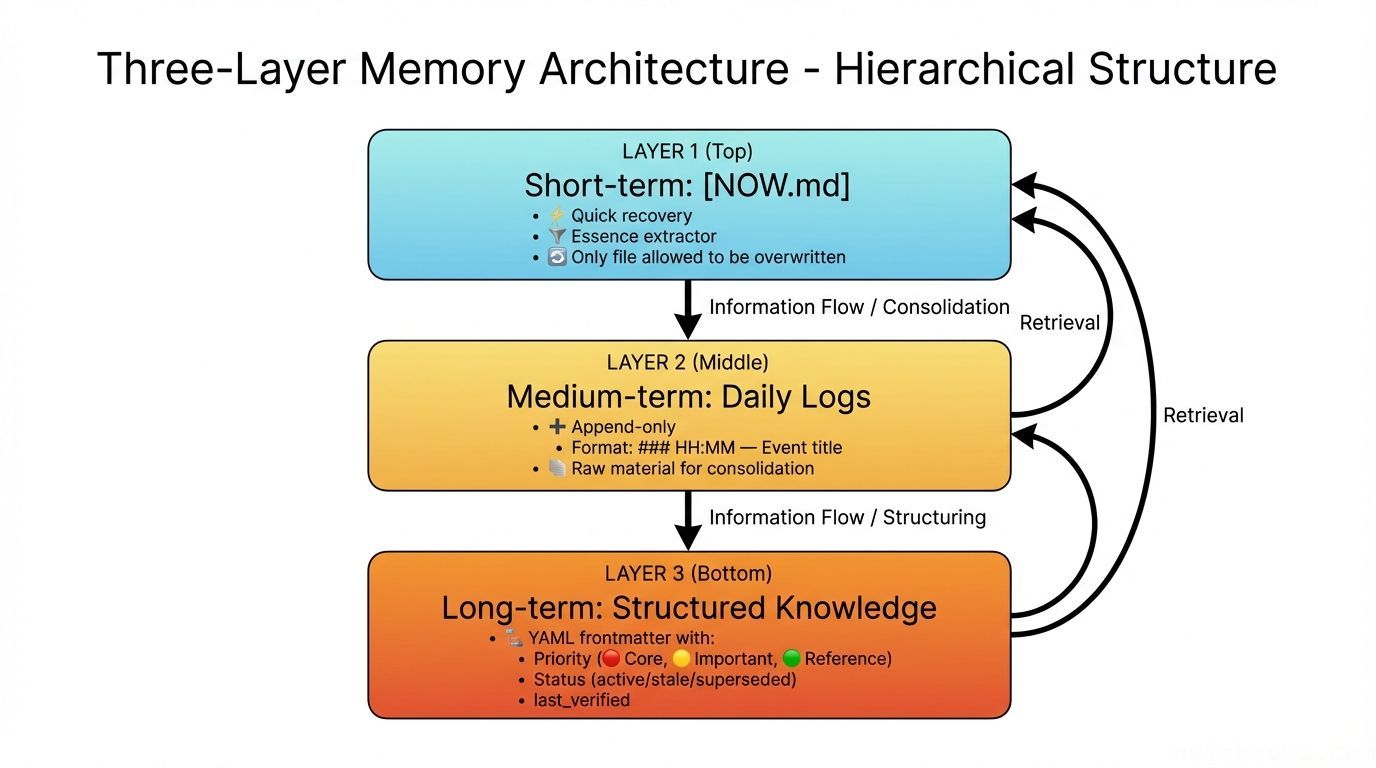
The Solution: Three-Layer Memory Architecture
Synthesizing all the research above plus my own hands-on experience, here’s a deterministic, zero-cost architecture for individual users.
First, let me show you my own memory system directory structure:
|
|
Let’s walk through each layer.
Short-term layer: NOW.md (the most overlooked design)
NOW.md is the highest information-density file in the entire architecture.
The core idea is straightforward: after every restart, the agent’s first action should be reading NOW.md — not searching through a massive memory library. It’s the essence extractor, the “where did I leave off” quick-recovery tool, the life raft after compaction.
|
|
Key rule: NOW.md is the only file allowed to be overwritten. All other memory files are append-only.
Medium-term layer: Daily logs
- Filename:
memory/YYYY-MM-DD.md - Write mode: Append-only, never overwrite
- Format suggestion:
### HH:MM — Event title + content description - Principle: Better too much than too little. Logs are raw material; distillation happens through nightly automation.
Long-term layer: Structured subdirectories
Knowledge files use a standardized YAML frontmatter:
|
|
Entries with last_verified older than 30 days are auto-flagged as ⚠️ stale, prompting manual review.
INDEX.md: Knowledge base health dashboard
|
|
On startup, the agent glances at INDEX.md and knows the health status of the entire knowledge base in seconds.
Lightweight Knowledge Graph: SQLite Triple Table
This is the most complex of the six flaws, and the fundamental limitation that pure Markdown cannot break through.
Why Do We Need a Knowledge Graph?
Markdown files can only store flat facts:
Brian prefers concise communication. Project X uses PostgreSQL. Tool Y requires an API Key.
But real-world knowledge has relationships:
Brian → responsible for → Project X → depends on → Tool Y → requires → API Key (stored in secrets/)
When the agent is asked “What API Key does Brian’s project need?”, pure vector search simply cannot complete this three-hop inference.
The solution: a SQLite triple table. No external dependencies, no deployment overhead — perfectly sufficient for personal knowledge relationship management:
|
|
Use Python or Node for reads, writes, and queries. The entire database is a single .db file sitting alongside your Markdown memory — portable and trivially easy to back up.
When to Write to the Knowledge Graph
Not all information deserves graphing. My recommendation is to limit it to these scenarios:
- System dependencies: Project A depends on tool B, which requires configuration C
- Resource locations: Where credentials / files / APIs are stored
- Historical associations: Decision X was made because of event Y
Daily facts (preferences, operation logs) are fine in Markdown — don’t over-graph.

Forgetting Mechanism: Active Forgetting Matters More Than Passive Retention
This might sound counterintuitive, but forgetting is one of the most critical capabilities of a memory system.
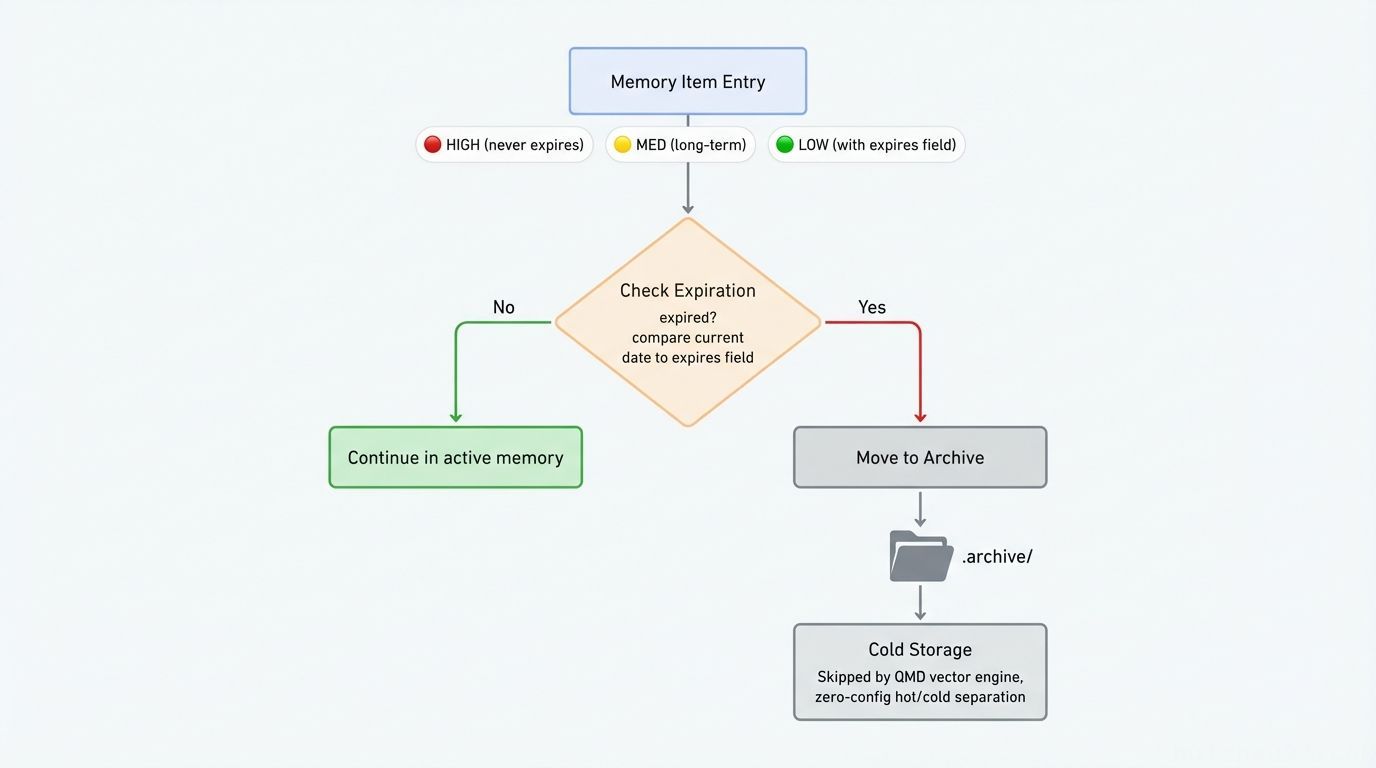
Each memory entry is tagged with priority and expiration:
|
|
The retention policy is simple:
|
|
.archive/ cold storage design: Name the directory with a dot prefix. OpenClaw’s QMD vector engine automatically skips dot-prefixed directories, giving you zero-configuration hot/cold index separation. Archived files aren’t deleted — they remain directly accessible via the filesystem.
A simple weekly cron script handles cleanup: scan for expired expires: fields, move those entries into .archive/, and update INDEX.md accordingly.
Automatic Consolidation: Teaching Your Memory System to Digest
Good storage structure alone isn’t enough — if memories can’t auto-consolidate, it’s just a manually maintained folder.
Temporal annotation is key. Every memory entry must include time-relationship markers, solving the “no temporal reasoning” problem mentioned earlier:
- “First appeared: …”
- “Following previous X, today completed Y”
- “N days since first discussion, status: completed”
Nightly consolidation (via cron): Set up a nightly cron job that calls your existing LLM API to:
- Read today’s daily log (
memory/YYYY-MM-DD.md) - Extract key decisions, lessons learned, and status changes
- Promote important entries to long-term knowledge files (with proper YAML frontmatter)
- Update
NOW.mdwith tomorrow’s priorities - Update
INDEX.mdhealth dashboard
One easy pitfall here: always read the target file before writing, check whether similar content already exists, and avoid duplicate entries and memory conflicts (a.k.a. the HaluMem problem).
The Setup Checklist
Here’s everything you need to implement this architecture:
- Three-layer file structure:
NOW.md+memory/YYYY-MM-DD.md+ structured subdirectories (lessons/,tools/, etc.) INDEX.md: Knowledge base health dashboard, read on startup- Nightly cron job: Calls your existing LLM API for auto-consolidation
expiresfield + weekly cleanup script: Active forgetting mechanism- Built-in vector search: No extra deployment (OpenClaw ships with it)
- SQLite triple table (optional): Only add if you genuinely need multi-hop relational reasoning
No extra resources needed — everything runs on what you already have.
Three Common Misconceptions
In practice, I’ve seen plenty of people stumble into these traps. Here are the three most common:
Misconception #1: More memory is always better. Quite the opposite — stale, low-quality memories are more dangerous than no memory at all. They masquerade as “facts” and skew the agent’s judgment. Forgetting mechanisms are just as important as writing mechanisms.
Misconception #2: Write-only, never read. Writing information into memory doesn’t mean the agent will use it. Serial Collapse — where agents gradually stop querying memory — is a real phenomenon. Regularly verifying that the agent actually uses its memory is as critical as building the memory system itself.
Misconception #3: Everything belongs in the knowledge graph. The value of a knowledge graph lies in relational reasoning, not storage. Daily preferences and operation logs are perfectly fine in Markdown — only knowledge that genuinely requires multi-hop reasoning deserves to be graphed.
Summary
A good memory system isn’t the one that stores the most — it’s the one that delivers the right information, in the right form, at the right moment.
Start with the three-layer architecture (NOW.md + daily logs + structured long-term files), add nightly auto-consolidation and a simple forgetting mechanism — for any individual user, this is more than enough, and it costs nothing beyond your existing LLM API. Add a SQLite triple table only when you genuinely need multi-hop relational reasoning.
Don’t overcomplicate it. The architecture above addresses all six fundamental flaws — and you can set it up in an afternoon.
You can also just copy this article to OpenClaw and let it set everything up for you.
- Long Time Link
- If you find my blog helpful, please subscribe to me via RSS
- Or follow me on X
- If you have a Medium account, follow me there. My articles will be published there as soon as possible.