
Map-Reduce is a programming paradigm used for processing large-scale datasets. It helps simplify the process of parallel computation and improves computational efficiency.
First, let’s understand the concepts of Map and Reduce.
- Map: In the Map phase, the input dataset is divided into a series of key-value pairs, and the same operation is applied to each key-value pair. This operation can be a function or a code block used to process each key-value pair and generate intermediate results.
- Reduce: In the Reduce phase, the intermediate results generated in the Map phase are combined and processed to obtain the final output result. In the Reduce phase, we can aggregate, summarize, or perform other operations on intermediate results with the same key.
The core idea of the Map-Reduce programming paradigm is “divide and conquer.” It allows us to break down complex computational tasks into multiple independent subtasks, process these subtasks in parallel, and then merge the results to obtain the final result.
Basic Example
Here is a simple example demonstrating the workflow of Map-Reduce:
|
|
In this example, we define a MapFunction that takes a string array and converts each element to uppercase using a custom function fn, returning a channel. The ReduceFunction takes a channel and a custom function fn to concatenate the results and print them out.
The following image provides a metaphor that vividly illustrates the business semantics of Map-Reduce, which is very useful in data processing.
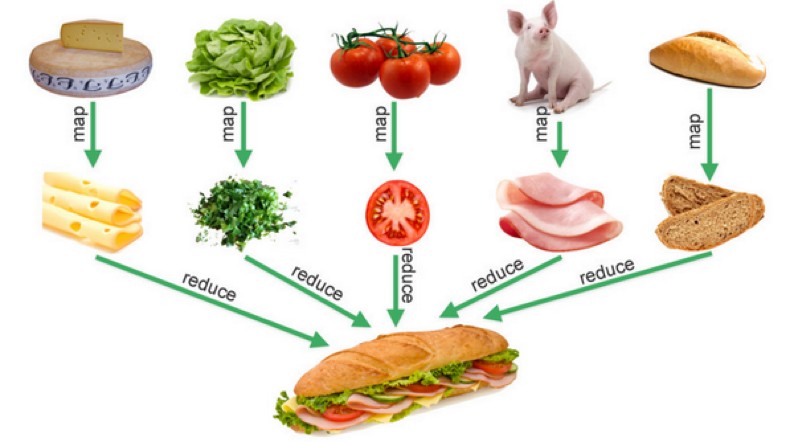
You may understand that Map/Reduce is just a control logic, and the real business logic is defined by the data and the function passed to them. Yes, this is a classic programming pattern of separating “business logic” from “control logic.” Now let’s take a look at a code example with meaningful business logic to reinforce the understanding of separating “control logic” and “business logic.”
Business Example
Employee Information
First, we have an employee object and some data:
|
|
Related Reduce/Filter Functions
|
|
Here’s a brief explanation:
EmployeeCountIfandEmployeeSumIfare used to count the number of employees or calculate the total based on a certain condition. They represent the semantics of Filter + Reduce.EmployeeFilterInfilters the employees based on a certain condition. It represents the semantics of Filter.
Now we can have the following code:
1) Count the number of employees over 40 years old:
|
|
2) Count the number of employees with a salary greater than 6000:
|
|
3) List employees who have not taken any vacation:
|
|
The Map-Reduce programming paradigm divides the computational task into Map and Reduce phases. Although writing single-machine code may not be faster than a simple for loop and may appear complex, in the era of cloud-native computing, we can leverage parallel computation and shared data access to improve computational efficiency. It is a powerful tool suitable for handling large-scale data and parallel computing scenarios, such as the original Google PageRank algorithm. The main purpose of learning it is to understand its mindset.