原文链接:https://kmcd.dev/posts/grpc-the-ugly-parts/
这篇文章是gRPC:好与坏系列的一部分。
gRPC无疑是微服务领域中的一把利器,它带来了效率和性能上的优势,但gRPC也有其丑陋的一面。作为一个在gRPC上花费了大量时间的人,我想揭示这项技术的一些不那么美好的方面。我已经讨论过gRPC的优点和缺点,现在让我们来谈谈它的丑陋之处。
代码生成
首先,我不得不说一下从protobuf生成的代码有多么丑陋。这些代码通常很冗长、复杂且难以阅读。尽管它并不是为了手动编辑而设计的,但这会影响代码的可读性和可维护性,尤其是在将gRPC集成到大型项目中时。最近在大多数语言中,这种情况已经有所改善,但仍然存在一些粗糙的地方。
语言特定的怪癖
protobuf和gRPC的初始实现常常偏离语言特定的规范,尤其是在HTTP处理方面。这在一定程度上源于强制支持HTTP/2的决定,这一决定后来被证明限制了gRPC在前端的应用。我们现在从gRPC-Web中了解到,trailer并不是像gRPC这样的协议的硬性要求。在这一决定之后,我们现在需要改进protobuf和gRPC的语言实现,使其更符合每种语言的习惯。
对于Go语言来说,避免使用net/http包是一个艰难的决定,因为这使得在与其他类型的HTTP API一起使用gRPC端点时变得更加困难,并且难以复用HTTP中间件。他们最终在grpc-go中添加了一个ServeHTTP()接口,作为使用Go标准库中的HTTP服务器的一种实验性方法,但使用这种方法会导致显著的性能损失。也许他们这样做是出于性能考虑?如果是这样,这无疑是一个将gRPC与Go生态系统其他部分割裂的权衡。
有时,语言特定的怪癖实际上会影响你如何设计protobuf类型。如果你遵循Buf的风格建议,枚举的名称应该以枚举名的大写蛇形版本作为前缀,就像这样:
|
|
这在buf的lint规则描述中有更好的解释,但这种风格指南之所以如此,是因为C++的枚举作用域规则,这使得在同一包中无法有两个具有相同枚举值名称的枚举值。虽然这种约定源于C++的作用域规则,但它影响了你应该如何设计所有的protobuf文件。为什么枚举内部的作用域不足以让C++编译器生成唯一的名称?为什么这种缺陷会影响风格指南,并进而影响所有目标语言?对我来说,这有点丑陋,因为某些语言实现的怪癖以不直观的方式冒了出来。
生成的代码甚至不够快
生成代码的一个好处是,你可以生成一些正常人不会写的代码,以获得一些性能优化。然而,如果你查看一些从protobuf生成的代码,你会发现大量使用了运行时反射。为什么?在某种程度上,我是在说生成的代码不够丑陋。让我们看一个具体的例子。请注意,这将是一个非常Go特定的部分,因为我大部分关于protobuf的经验都是在Go中。然而,相同的策略已经应用于大多数语言。
让我们来看一个Go中的超级简单示例。以下是protobuf:
|
|
这是由protoc生成的类型:
|
|
实际上,并没有为这个类型定义专门的Marshal()或Unmarshal()函数。这意味着序列化是通过运行时反射来实现的。反射通常被认为较慢,因为它确实较慢。我觉得奇怪的是,没有为Go生成优化的、类型特定的序列化代码。话虽如此,你可以通过使用一个名为vtprotobuf的单独protoc插件来获得这一点,该插件将为每个protobuf类型生成专门的marshal和unmarshal函数。它还允许使用类型特定的内存池,这也有助于减少分配并提高性能。根据我的测试,只需添加vtprotobuf而不做任何代码更改,就可以将性能提高2-4%。这基本上是“免费”的2-4%,所以我觉得很奇怪,这竟然不是标准编译器的一部分。你可能不喜欢它,但这就是峰值性能的样子。无论如何,这个项目需要更多的关注和支持。
请注意,还有其他一些项目声称在标准protobuf库的基础上取得了惊人的性能提升。他们确实通过做出一些权衡来实现这些性能提升,但很多时候,额外的复杂性是值得的。
你可能会读到这一部分并想:“好吧,这会增加生成的代码量,增加二进制文件或包的大小,在某些环境中,你可能不希望这样。”这是事实,这就是为什么protobuf有一个optimize_for选项,所以你可以注释以下之一:
option optimize_for = SPEED;- 更冗长、更快的代码option optimize_for = CODE_SIZE;- 更小的代码option optimize_for = LITE_RUNTIME;- 旨在在较小的运行时上运行,省略了描述符和反射等功能。
请参阅官方protobuf文档中关于optimize_for的完整描述。虽然这些选项存在,但它们实际上并没有用于大多数目标语言。将来,我完全希望看到大部分vtprotobuf被整合到Go的标准protobuf编译器中,并在optimize_for = SPEED时使用。将类似vtprotobuf的优化整合到标准protobuf编译器中,可以为Go带来显著的性能提升,其他语言也可能存在类似的机会。
必填字段
Protobuf的维护者在必填字段方面学到了一些艰难的教训。他们觉得自己犯了一个严重的错误,以至于他们推出了一个新版本的protobuf,即proto3,只是为了从规范中删除必填字段。为什么?“必填字段有害”宣言的作者在一篇冗长的Hacker News评论中谈到了这一点,但重要的是:
现实世界的实践也表明,许多最初被认为是“必填”的字段随着时间的推移往往会变成可选的,因此有了“必填字段有害”的宣言。在实践中,你希望将所有字段声明为可选的,以便为变化提供最大的灵活性。
这一点在官方protobuf风格指南中得到了呼应,他们建议添加注释来指示某个字段是必填的。如果我们讨论的是将消息从A传递到B,我完全同意这种思路。然而,仅仅因为某些字段被认为是“必填”的会随着时间的推移而变化,并不意味着必填字段不存在。仍然需要代码来强制执行这一要求,老实说,我不想编写这些代码。因此,我认为在不编写大量空检查的情况下处理必填字段的最佳方法是使用protovalidate或类似的库,这些库具有protobuf选项,允许你注释哪些字段是必填的。然后在服务器和/或客户端上有代码可以使用库来强制执行这些要求。在我看来,这兼具了两者的优点:你仍然可以以不会完全破坏消息完整性的方式声明必填字段。
我不喜欢这样:
|
|
我喜欢这样:
|
|
我是protovalidate的忠实粉丝,我已经多次使用它并为其做出了贡献。一般来说,我认为protobuf字段的自定义选项是protobuf的一个未被充分利用的超能力。
难以入门
尽管gRPC具有不可否认的优势,但其学习曲线可能很陡峭。对于新手来说,开始使用protobuf、理解工具链以及设置必要的基础设施可能会让人望而生畏,这使得初始采用的障碍比使用更简单的基于JSON的API更高。为什么它如此陡峭?嗯,它在大多数语言中引入了非惯用的工具链。有一些语言支持的例子使得protobuf生成变得无缝。Grpc.Tools for .NET就是一个闪亮的例子,展示了如何将protobuf工具链更紧密地集成到标准语言工具链中。我们需要更多这样的例子。
当许多使用和依赖protobuf和gRPC的人积极不希望gRPC扩展到前端,并认为推动这一方向会导致不了解情况的人侵入后端领域时,陡峭的学习曲线并没有帮助,他们认为只有他们足够聪明才能在后端工作。这是精英主义的守门行为,不幸的是,这种行业普遍存在。我相信gRPC在Web前端中与在微服务中一样有其地位。
我通过帮助其他人使用protobuf学到了很多。你可能会在Buf的Slack频道或相关讨论中看到我,因为我确实从中受益匪浅。许多文章的想法直接来自于在那里回答问题。如果我看到某个问题出现的频率足够高,我可能会写一篇文章来讨论它。我认为protobuf和gRPC社区需要更多这种态度。
我相信陡峭的学习曲线(可以通过工具链来缓解),加上一些后端开发者的抵制(可以通过……同理心来缓解?),已经减缓了它在Web开发中的广泛采用。
gRPC有其历史
gRPC最初专注于微服务,并且与HTTP/2的紧密联系阻碍了它在Web开发中的广泛采用。即使有了gRPC-Web的出现,仍然有一种看法认为它在前端生态系统中并不是一等公民。与TanStack Query等流行前端库缺乏强大的集成进一步巩固了这种看法。

我认为通过改进工具链,有真正的机会让更多前端开发者对gRPC感到兴奋。目前,整个行业正在围绕“前端”和“后端”之间的界限进行一场巨大的讨论,我认为无论结果如何,我们都会看到更多使用gRPC的TypeScript代码。
gRPC中的“g”
虽然gRPC项目声称 gRPC中的“g”是一个反向缩略词,代表“gRPC”,但它最初代表Google,因为是Google开发并发布了protobuf和gRPC。

关于Google对gRPC和protobuf的长期承诺,始终存在一个悬而未决的问题。他们会继续投资于这些开源项目,还是会在优先级发生变化时突然撤资?请记住,Google最近裁掉了Flutter、Dart和Python团队的大部分成员。Protobuf社区正在发展,但它是否足够自给自足以应对这种情况?
它尚未完成
其他人说gRPC不成熟,不是因为它的年龄,而是因为它的生态系统发展程度。我倾向于同意,因为它缺少我期望在一个成熟生态系统中看到的功能和工具。
缺少包管理器
在没有专门工具的情况下,跨多个项目或仓库共享protobuf定义是一个持续的挑战。虽然像Bazel、Pants和Buf的BSR这样的解决方案存在,但我在“现实世界”中使用protobuf的经验……参差不齐。有一些由Google开发的开源项目,它们使用bash脚本拼凑在一起,在手动调用protoc之前下载依赖项。想象一下,一个编程语言没有管理依赖项的解决方案。这太疯狂了。我认为Bazel和Buf工具链很好地解决了这个问题,但我只是感到沮丧,我遇到的每个使用protobuf的仓库都以最定制化的方式解决了这个问题。社区需要团结起来改进这一点。有一个名为Buffrs的开源仓库似乎正在解决这个问题。我还没有亲自使用过它,但到目前为止它看起来还不错。
关于依赖项,我想指出的是,Google的“众所周知的”protobuf类型享有被内置到protoc中的特权。虽然这些类型非常有用且无价,但它们的特权使得其他有用的protobuf类型库难以存在和繁荣。仅仅将这些protobuf定义内置到protoc(和其他工具链中)是对没有真正和一致的依赖管理故事的逃避。
编辑器支持
Protobuf代码生成的编辑器集成还有很多不足之处。如果编辑器能够智能地将生成的代码链接回其protobuf源,那将非常有帮助。这将提供更无缝的体验,但工具链还不够智能。此外,我认为每个人都应该使用Buf的编辑器支持。如今,开发者期望在编辑器中内置linter和自动格式化工具。而对于protobuf来说,有非常真实的原因需要遵循linter的建议。
像tRPC这样的项目展示了紧密集成和意见化设计选择的好处——这是protobuf由于其性质无法完全复制的。然而,我仍然希望protobuf生态系统能够发展,提供类似的简化开发者体验。
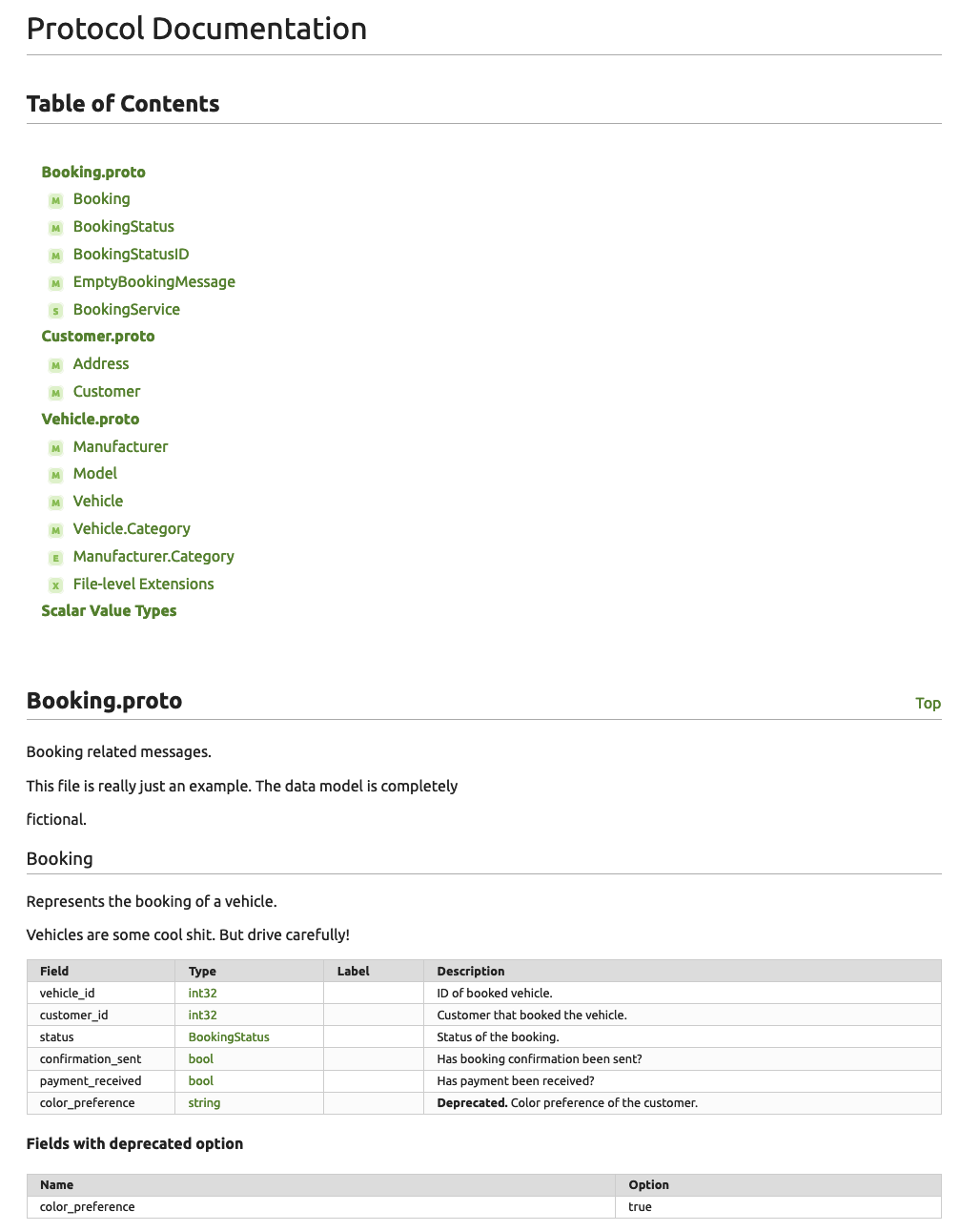
丑陋的文档
我从未见过从protobuf生成的文档不是超级丑陋的。我认为,由于gRPC历来是后端服务,后端开发者从未真正努力使用protoc插件生成漂亮的文档输出。我通过制作一个protoc插件解决了这个问题,该插件可以从给定的protobuf文件生成OpenAPI。然后我使用众多漂亮的工具之一来显示OpenAPI规范。这远比让我设计一个像样的文档容易得多。从protobuf生成OpenAPI的另一个附带好处是能够利用该生态系统,因为它不仅仅是文档。
让我们看一个真实的例子。这是使用少数几个从protobuf生成文档的工具之一,protoc-gen-doc生成的文档:
将其与一些OpenAPI工具链进行比较。这是使用Elements生成的,但还有许多其他同样精美的替代方案:
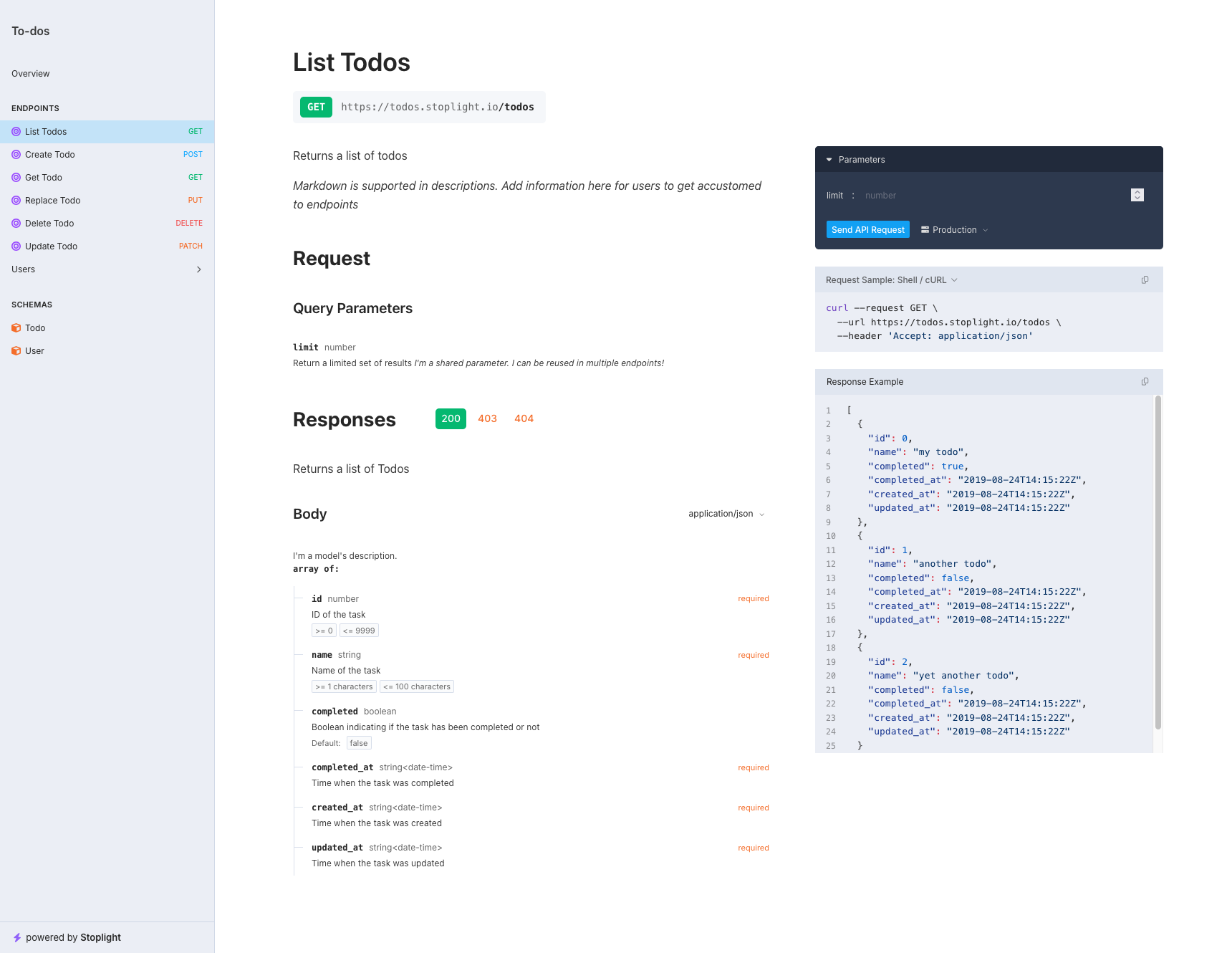
指责单个插件并说默认模板不如OpenAPI替代品好看有点不公平,因为实际上你确实在protoc-gen-doc中有更多的灵活性。它允许你指定自己的模板,因此它可以像你希望的那样漂亮。然而,这确实符合我的观点:在REST世界中,工具链比gRPC更完善和精致。这是一个可以解决的问题,但我们需要让前端开发者和设计师对gRPC感到兴奋,或者后端工程师需要开始磨练他们的设计技能。
我还想指出,OpenAPI/Swagger接口通常有一种方法可以直接从文档网站测试端点。这在gRPC世界中的等效工具中是完全缺失的。此外,使用大多数OpenAPI文档工具,你可以清楚地看到哪些字段是必填的,并会显示具有约束的字段。因此,它不仅更漂亮,而且功能也更强大。
结论
gRPC虽然在许多方面是一个强大的工具,但仍然有成长的空间。生成代码的不理想之处,加上依赖项管理和protobuf模式演变的挑战,可能会给开发者带来摩擦。缺乏直观的编辑器集成以及历史上对后端服务的关注,也阻碍了它在Web开发中的广泛采用。
然而,我认为gRPC的未来是光明的,并且可以变得不那么丑陋。社区正在积极应对这些挑战,开发诸如buf CLI、protovalidate和protoc-gen-connect-openapi等工具来弥合差距并增强开发者体验。随着gRPC的成熟和其生态系统的扩展,我们可以期待改进的工具链、更好的编辑器支持以及更顺畅地融入前端世界。