什么是 一致性hash 算法
首先摘抄一段维基百科的定义
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对𝐾/𝑛 个关键字重新映射,其中 𝐾 是关键字的数量,𝑛是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。 — wikipedia
分布式系统中, 一致性hash无处不在,CDN,KV,负载均衡等地方都有它的影子,是分布式系统的基石算法之一。一致性hash 有以下几个优点。
- 均衡负载: 一致性哈希算法能够将数据在节点上均匀分布。
- 扩展性: 在一致性哈希算法中,当节点数量增加或减少时,只有部分数据需要重新映射,系统能够进行水平扩展更容易,可以增加节点数量以应对更大的负载需求;
- 减少数据迁移: 相比传统的哈希算法,一致性哈希算法在节点增减时需要重新映射的数据量较少,可以大幅降低数据迁移的开销,减少系统的不稳定性和延迟;
本篇文章的目标就是学习一致性hash 算法以及它的简单实现。
This article is first published in the medium MPP plan. If you are a medium user, please follow me in medium. Thank you very much.
一致性hash算法的原理
基本一致性hash 算法
最基础的一致性 hash 算法就是把节点直接分布到环上,从而划分出值域, key 经过 hash( x ) 之后,落到不同的值域,则由对应的节点处理。最常见的值域空间大小是:2^32 - 1,节点落到这个空间,来划分不同节点所属的值域。如图所示。
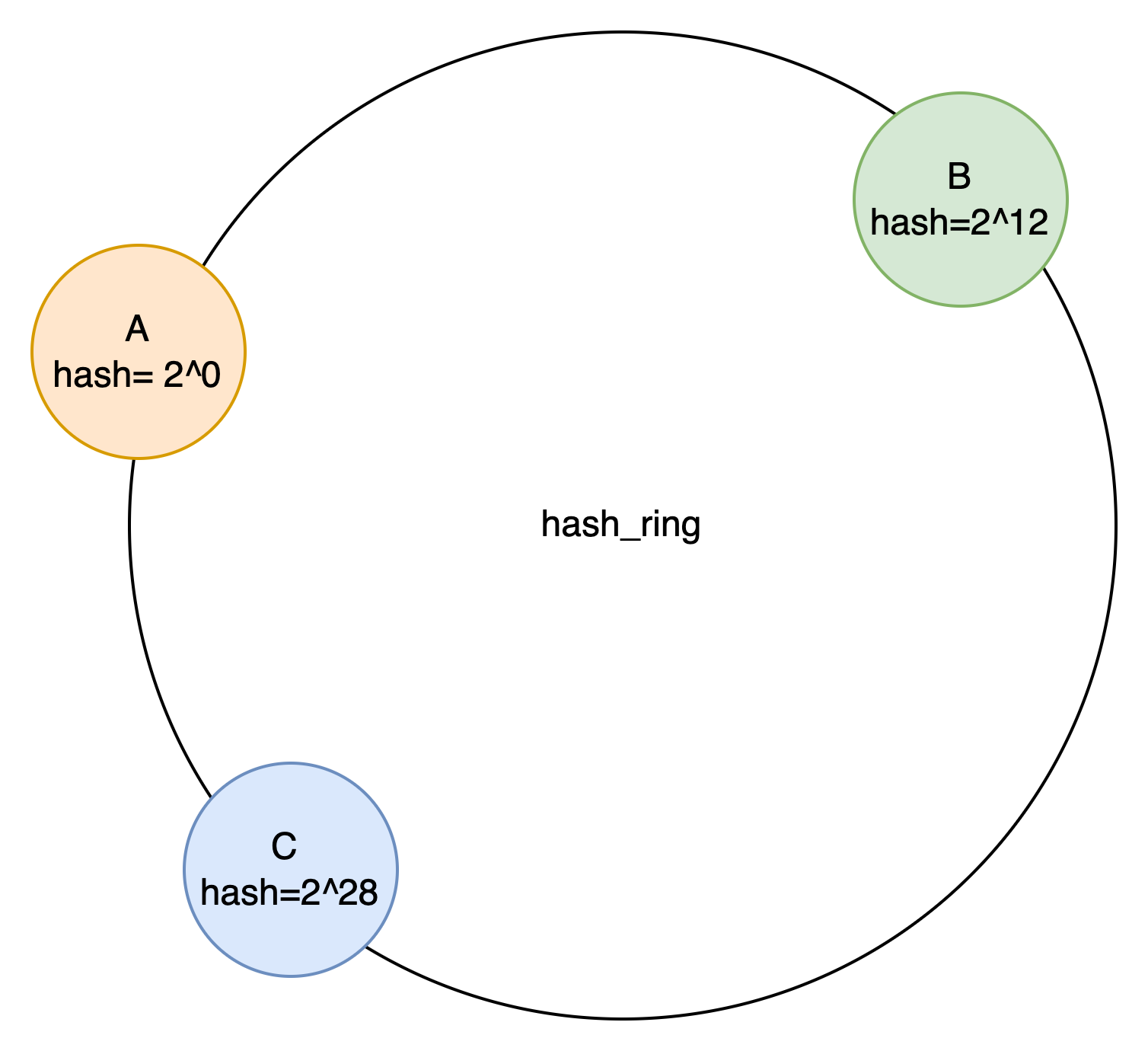
Node A 存储 的 hash 范围为 [0,2^12) .
Node B 存储 的 hash 范围为 [2^12,2^28) .
Node C 存储 的 hash 范围为 [2^28,0) .
上述基本的一致性哈希算法有明显的缺点:
- 随机分布节点的方式使得很难均匀的分布哈希值域,从上面可以看出,三个节点存储的数据不均匀。
- 在动态增加节点后,原先的分布就算均匀也很难再继续保证均匀;
- 增删节点带来的一个较为严重的缺点是:
- 当一个节点异常时,该节点的压力全部转移到相邻的一个节点;
- 当一个新节点加入时只能为一个相邻节点分摊压力;
虚拟节点
Go语言之父 rob pike 曾今说过 计算机领域里,没有什么问题是加一层间接寻址解决不了的. 一致性hash 也是一样。
如果三个节点 存在不均衡的问题,那么我们就把他虚拟成N个节点。A[a1,a2….a1024], 然后将他们映射到hash_ring 上,就是这样样子的。
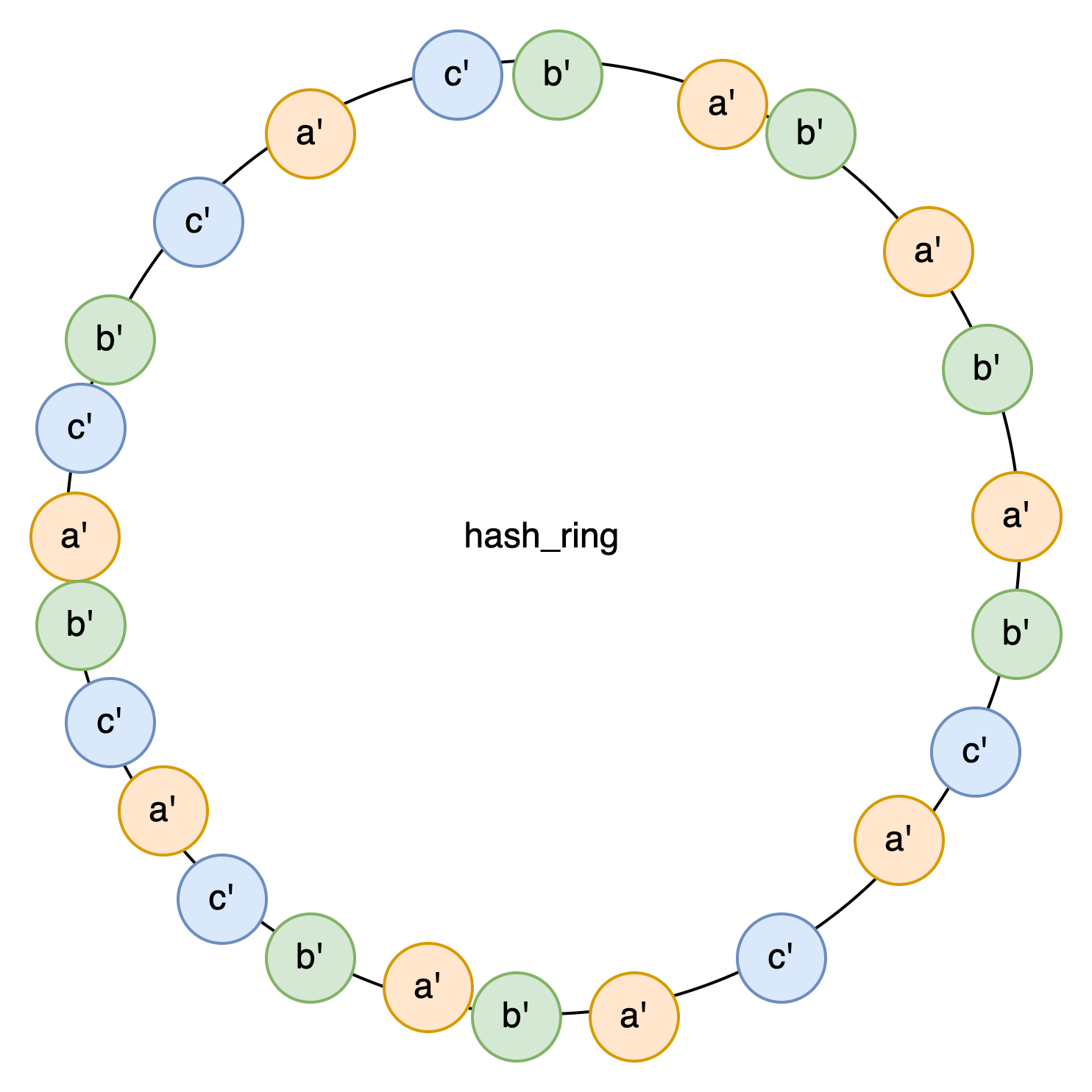
每个虚拟节点都有对应的hash区间。负责一段key,然后根据虚拟node 的名字找到对应的物理node读写数据。
引入虚拟节点后,就完美的解决了上面的三个问题。
- 只要我们的虚拟节点足够多,各个节点的数据就能平衡,(⚠️:这个在工程上是有代价的)
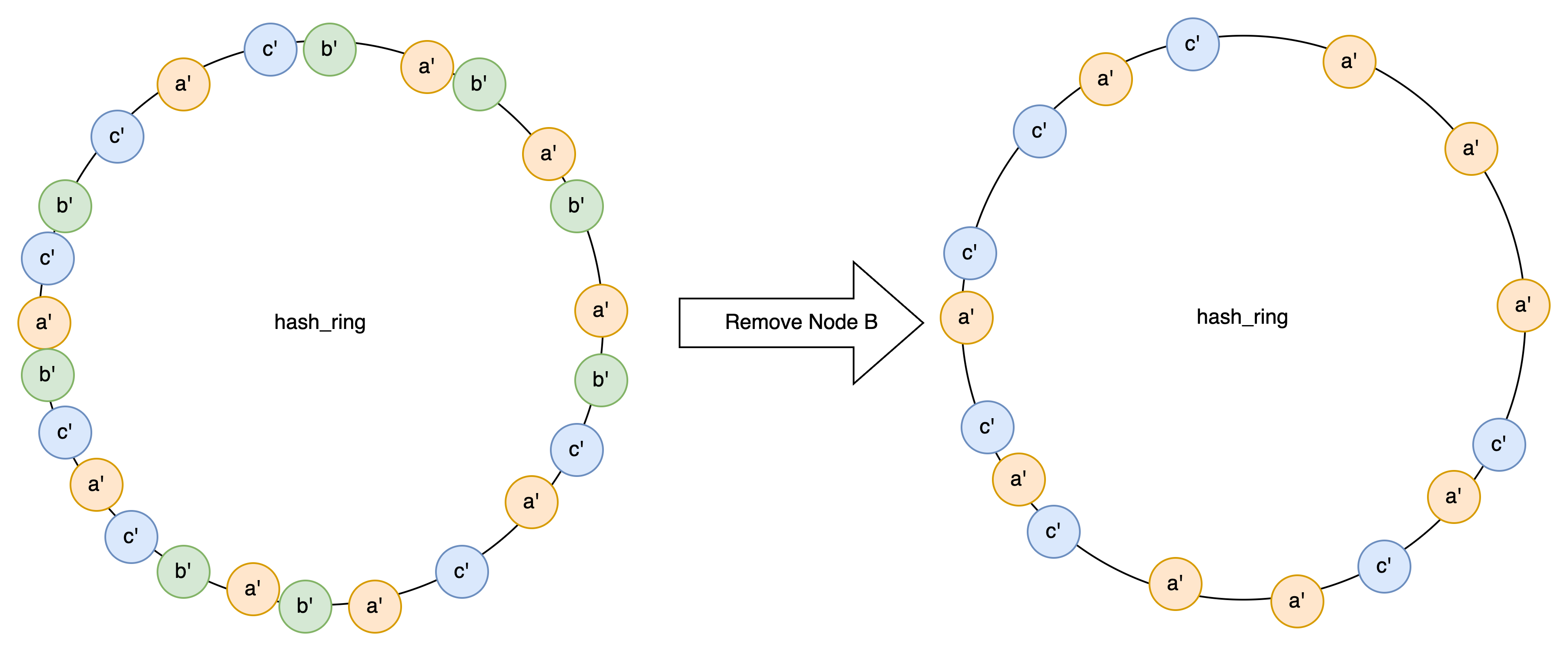
- 如果一个节点宕机了,它的数据会均衡的分布到整个集群所有节点,同理,新增的节点 也能负担所有节点的压力。
Go语言实现
完整的代码:https://github.com/hxzhouh/blog-example/tree/main/Distributed/consistent_hashing
首先定义一个hash_ring, 使用 crc32.ChecksumIEEE 作为默认的hash function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
type VirtualNode struct { // 虚拟节点
Hash uint32
Node *Node
}
type Node struct { // 物理节点
ID string
Addr string
}
type HashRing struct {
Nodes map[string]*Node
VirtualNodes []VirtualNode.
mu sync.Mutex
hash HashFunc
}
func NewHashRing(hash HashFunc) *HashRing {
if hash == nil {
hash = crc32.ChecksumIEEE
}
return &HashRing{
Nodes: make(map[string]*Node),
VirtualNodes: make([]VirtualNode, 0),
hash: hash,
}
}
|
我们来看一下怎么添加节点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func (hr *HashRing) AddNode(node *Node) {
hr.mu.Lock()
defer hr.mu.Unlock()
hr.Nodes[node.ID] = node
for i := 0; i < VirtualNodesPerNode; i++ {
virtualNodeID := fmt.Sprintf("%s-%d", node.ID, i)
hash := hr.hash([]byte(virtualNodeID))
hr.VirtualNodes = append(hr.VirtualNodes, VirtualNode{Hash: hash, Node: node})
}
sort.Slice(hr.VirtualNodes, func(i, j int) bool {
return hr.VirtualNodes[i].Hash < hr.VirtualNodes[j].Hash
})
}
|
我们每添加一个节点,就要创建对应数量的虚拟节点,并且要保证虚拟节点有序(这样才能查找)
同样,remove 的时候,也需要删除虚拟节点
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func (hr *HashRing) RemoveNode(nodeID string) {
hr.mu.Lock()
defer hr.mu.Unlock()
delete(hr.Nodes, nodeID)
virtualNodes := make([]VirtualNode, 0)
for _, vn := range hr.VirtualNodes {
if vn.Node.ID != nodeID {
virtualNodes = append(virtualNodes, vn)
}
}
hr.VirtualNodes = virtualNodes
}
|
查询的时候,我们先找到对应的虚拟节点,然后再根据虚拟节点找到对应的物理节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func (hr *HashRing) GetNode(key string) *Node {
hr.mu.Lock()
defer hr.mu.Unlock()
if len(hr.VirtualNodes) == 0 {
return nil
}
hash := hr.hash([]byte(key))
idx := sort.Search(len(hr.VirtualNodes), func(i int) bool {
return hr.VirtualNodes[i].Hash >= hash
})
if idx == len(hr.VirtualNodes) {
idx = 0
}
return hr.VirtualNodes[idx].Node
}
|
最后我们来看看,业务如何使用 这个hash_ring
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
type KVSystem struct {
hashRing *HashRing
kvStores map[string]*kvstorage.KVStore
}
func NewKVSystem(nodes int) *KVSystem {
hashRing := NewHashRing(crc32.ChecksumIEEE)
for i := 0; i < nodes; i++ { // init node
node := &Node{
ID: fmt.Sprintf("Node%d", i),
Addr: fmt.Sprintf("192.168.1.%d", i+1),
}
hashRing.AddNode(node)
}
kvStores := make(map[string]*kvstorage.KVStore) //init storage
for id := range hashRing.Nodes {
kvStores[id] = kvstorage.NewKVStore()
}
return &KVSystem{
hashRing: hashRing,
kvStores: kvStores,
}
}
func (kv *KVSystem) Get(key string) (string, bool) { //get value
node := kv.hashRing.GetNode(key)
return kv.kvStores[node.ID].Get(key)
}
func (kv *KVSystem) Set(key string, value string) { // set value
node := kv.hashRing.GetNode(key)
kv.kvStores[node.ID].Set(key, value)
}
func (kv *KVSystem) Delete(key string) {
node := kv.hashRing.GetNode(key)
kv.kvStores[node.ID].Delete(key)
}
// DeleteNode 需要将存储在节点上的数据重新分配。
func (kv *KVSystem) DeleteNode(nodeID string) {
allData := kv.kvStores[nodeID].GetAll()
kv.hashRing.RemoveNode(nodeID)
delete(kv.kvStores, nodeID)
for key, value := range allData {
kv.Set(key, value)
}
}
func (kv *KVSystem) AddNode() {
node := &Node{
ID: fmt.Sprintf("Node%d", len(kv.hashRing.Nodes)),
Addr: fmt.Sprintf("192.168.1.%d", len(kv.hashRing.Nodes)+1),
}
kv.hashRing.AddNode(node)
kv.kvStores[node.ID] = kvstorage.NewKVStore()
}
|
这样我们就实现了一个最简单的基于一致性hash的kv 存储,是不是特别简单? 但是它却支撑了我们整个网络世界的运转。
参考资料
Consistent_hashing
- 本文长期连接
- 如果您觉得我的博客对你有帮助,请通过 RSS订阅我。
- 或者在X上关注我。
- 如果您有Medium账号,能给我个关注嘛?我的文章第一时间都会发布在Medium。
