
引言
Uber 重视可靠的数据湖(Data Lake),其分布在本地和云环境中。这种多区域架构在有限的网络带宽下为确保可靠且及时的数据访问带来了挑战,尤其是在灾难恢复(Disaster Recovery)场景中需要实现无缝的数据可用性。Uber 使用 Hive Sync 服务,该服务基于 Apache Hadoop® Distcp(Distributed Copy,分布式拷贝)进行数据复制。然而,随着 Uber 数据湖规模超过 350 PB,Distcp 的局限性逐渐显现。本文探讨了针对 Distcp 所做的优化,以提升其性能并满足 Uber 在分布式基础设施上日益增长的数据复制和灾难恢复需求。
理解 Distcp
Distcp 是一个开源框架,用于以分布式方式在不同位置之间复制大规模数据集。它利用 Hadoop 的 MapReduce 框架将拷贝任务并行化并分发到多个节点上,从而实现更快、更具扩展性的数据传输,尤其适用于大规模环境。
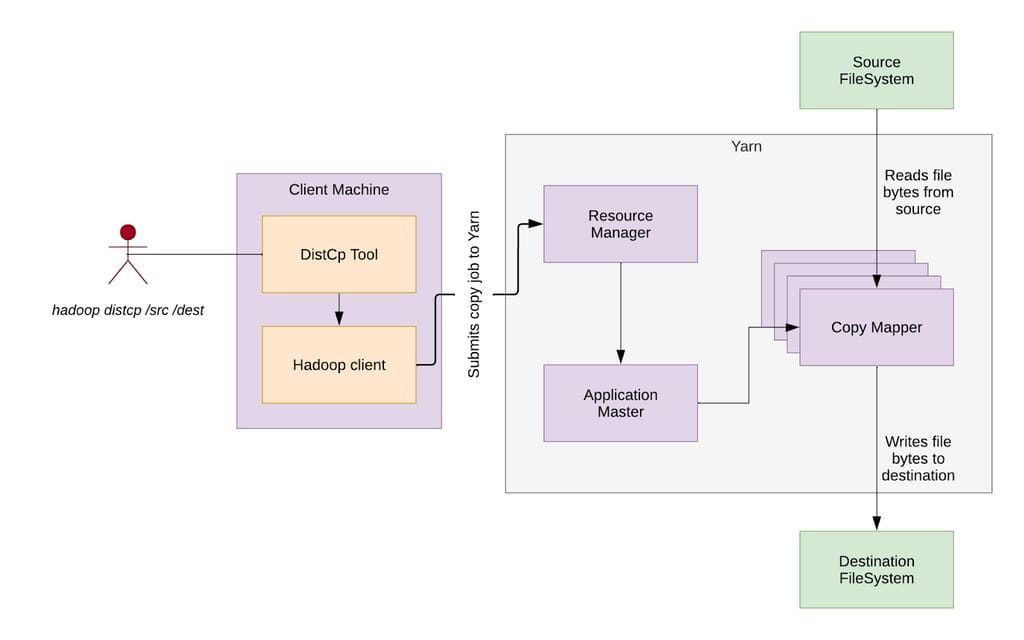
图 1:Distcp 高层架构。
Distcp 架构
Distcp 架构由以下几个关键组件组成:
- Distcp 工具(Distcp Tool): 识别文件,将其分组为块(拷贝清单,Copy Listing),定义跨 Mapper 的分发策略,并将配置好的 Hadoop 作业提交到 YARN。
- Hadoop 客户端(Hadoop Client): 设置作业环境,确定哪些 Mapper 处理特定的块(输入分片,Input Splitting),并将作业提交到 YARN。
- 资源管理器(RM,Resource Manager): YARN 组件,负责调度任务,接收 Distcp 作业,分配资源,并将执行委托给应用主节点。
- 应用主节点(AM,Application Master): 监控 MapReduce 作业的生命周期,为 Copy Mapper 任务向 RM 请求资源(容器),并在目标端合并文件分片。
- 拷贝映射器(Copy Mapper): 执行实际的数据块拷贝操作,运行在由 YARN Node Manager 管理的容器中。
- 拷贝提交器(Copy Committer): 合并已拷贝的数据块,在目标文件系统中组装最终文件。
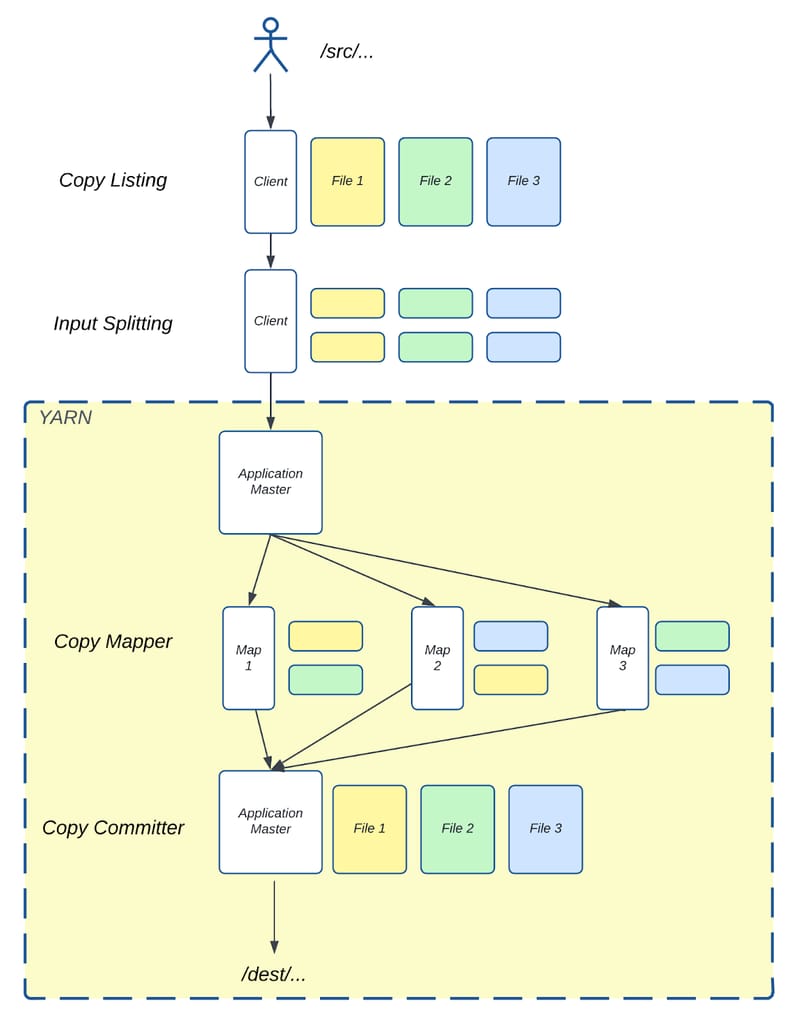
图 2:Distcp 从 /src/ 目录复制到 /dest/ 目录的示意图。
图 2 展示了 Distcp 如何使用上述组件将三个文件从源目录 /src/ 复制到目标目录 /dest/。源目录包含三个大小相同的文件——File 1、File 2 和 File 3。在客户端运行的拷贝清单任务识别这些文件并将每个文件分成两个块(Chunk)。输入分片任务随后将这些文件块分配给三个 Mapper。
- Map 1 接收 File 1 的一个块和 File 2 的一个块。
- Map 2 处理 File 3 的一个块和 File 1 的一个块。
- Map 3 处理 File 2 的一个块和 File 3 的一个块。
拷贝映射器任务随后将这些块从源目录复制到目标目录。复制完成后,拷贝提交器任务在 AM 中运行,合并每个文件对应的块,在目标目录中重建最终的三个文件。
HiveSync 如何使用 Distcp
HiveSync 最初基于开源的 Airbnb® ReAir 项目构建。它支持批量复制(一次性拷贝大量数据)和增量复制(随着新数据到达同步增量更新),使 Uber 的数据湖在 HDFS™(Hadoop Distributed File System,Hadoop 分布式文件系统)和基于云的对象存储之间保持同步。它使用 Distcp 进行大规模数据复制。
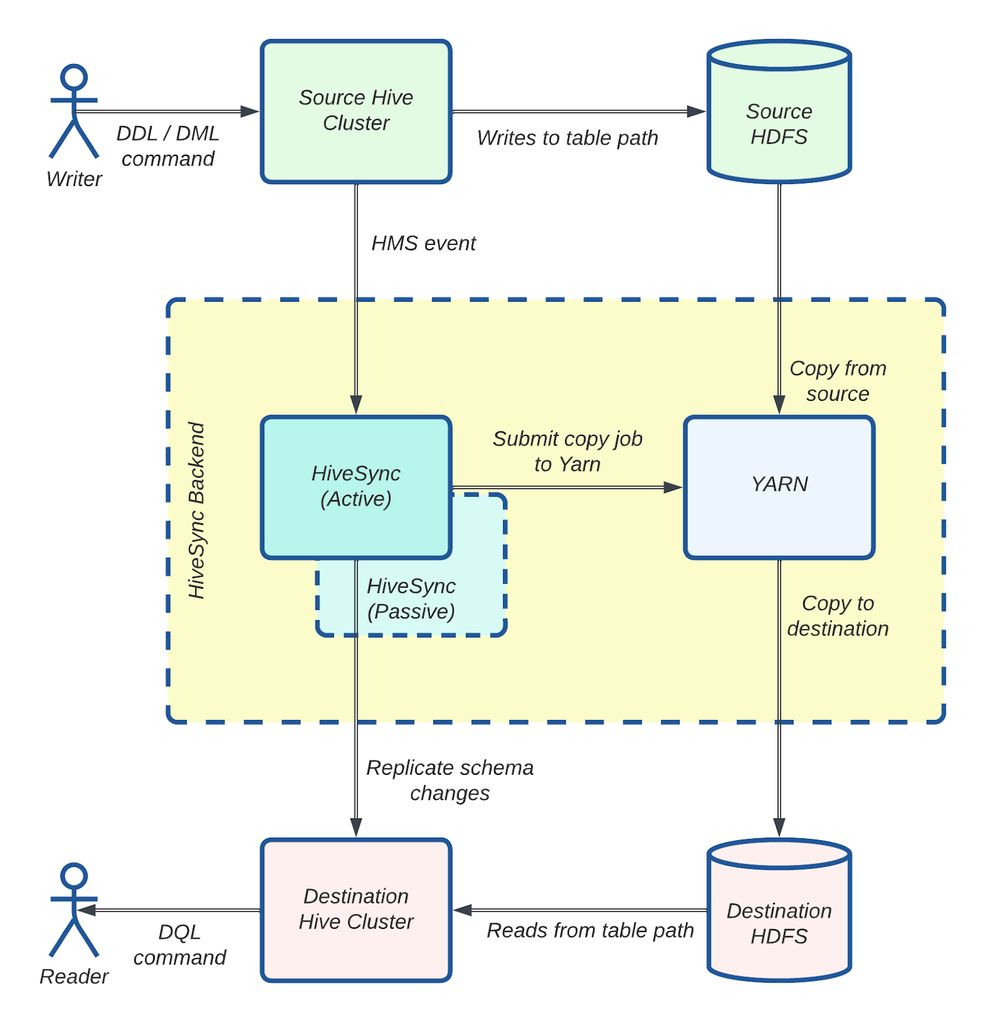
图 3:HiveSync 架构:使用 Distcp 的数据复制工作流。
图 3 展示了 HiveSync 服务器如何监听来自源 Hive 集群的拷贝请求。对于大于 256 MB 的数据,它将 Distcp 作业提交给执行器。多个 Worker(异步线程)随后并行准备并通过 Hadoop 客户端将这些作业提交到 YARN。监控线程跟踪每个作业的进度,作业成功完成后,数据即可在目标集群中使用。
HiveSync 的扩展性问题:临界点
到 2022 年第三季度,HiveSync 面临重大的扩展性挑战,因为每日数据复制量在仅一个季度内从 250 TB 激增至 1 PB。
导致这一快速增长的一个因素是数据写入集中在单个数据中心。2022 年,Uber 为节省成本转向了主动-被动(Active-Passive)数据湖架构,从均匀分布的数据生成模式转变为由主要的本地数据中心承担 90% 的数据生成和大部分批处理计算任务。这显著增加了 HiveSync 服务器从主区域向备用区域复制数据的负载。SRC(Single Region Compute,单区域计算)项目的影响将另行讨论。
另一个因素是将所有本地 Hive 数据集接入 HiveSync。在新的主动-被动模型下,HiveSync 成为灾难恢复的关键组件,确保在一个区域生成的数据能被复制到另一个地理区域。这要求 HiveSync 扩展到覆盖 Uber 的整个数据湖。仅在一个季度内,HiveSync 管理的数据集数量从 30,000 增长到 144,000,新数据集不断接入。这使复制请求数量增加了一倍多。
由此,每日复制作业数量从 10,000 飙升至平均 374,000,远远超出系统的处理能力。这导致了大量积压,使得满足承诺的复制延迟 SLA 变得越来越困难。具体而言,P100 复制延迟 SLA 4 小时和 P99.9 SLO 20 分钟在这一新规模下变得难以维持。
此外,随着 HiveSync 在将 Uber 数据湖从本地迁移到云区域中承担关键角色,复制请求的规模预计将大幅增加。预计拷贝请求的规模和数量将几乎翻倍,这对 HiveSync 管理增长的工作负载和优化数据复制流程以应对云基础设施运营挑战提出了更高要求。
关键改进
我们对 Distcp 进行了以下增强,以满足我们的扩展需求。这些优化显著提升了 Uber 数据复制的规模和效率。
具体包括:
- 将资源密集型的拷贝清单和输入分片任务转移到应用主节点,通过缓解 HDFS 客户端争用将作业提交延迟降低了 90%。
- 并行化拷贝清单和拷贝提交器任务,显著缩短了作业规划和完成时间。
- 为小规模传输实现 Uber 作业,帮助每天减少 268,000 次容器启动,优化了 YARN 资源使用。
下面详细介绍每项改进——
将 Distcp 准备任务转移到 AM
在一次故障事件中,我们注意到系统负载较高时,文件系统延迟的增加导致 Distcp 拷贝清单延迟相应上升。
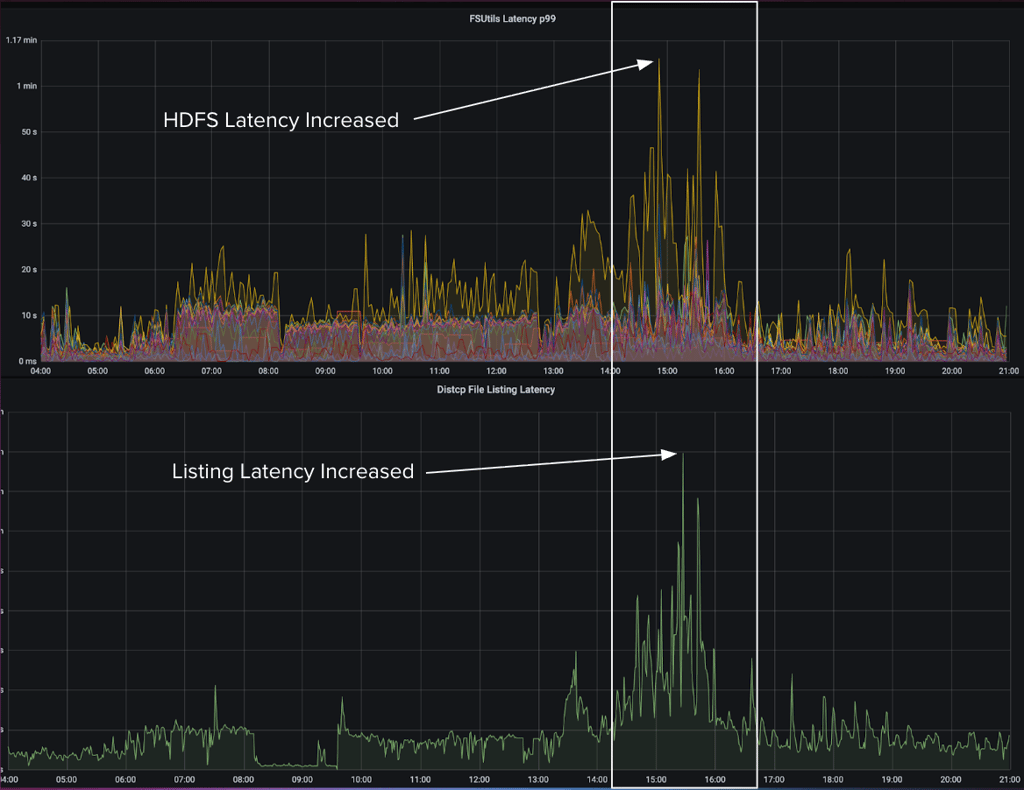
图 4:HDFS FSUtils 延迟增加直接影响 Distcp 拷贝清单任务。
当我们分析延迟峰值期间的线程转储时,发现大部分线程都在等待 HDFS 客户端持有的远程过程调用(RPC,Remote Procedure Call)锁。这种方式在高度多线程的环境中无法很好地扩展。
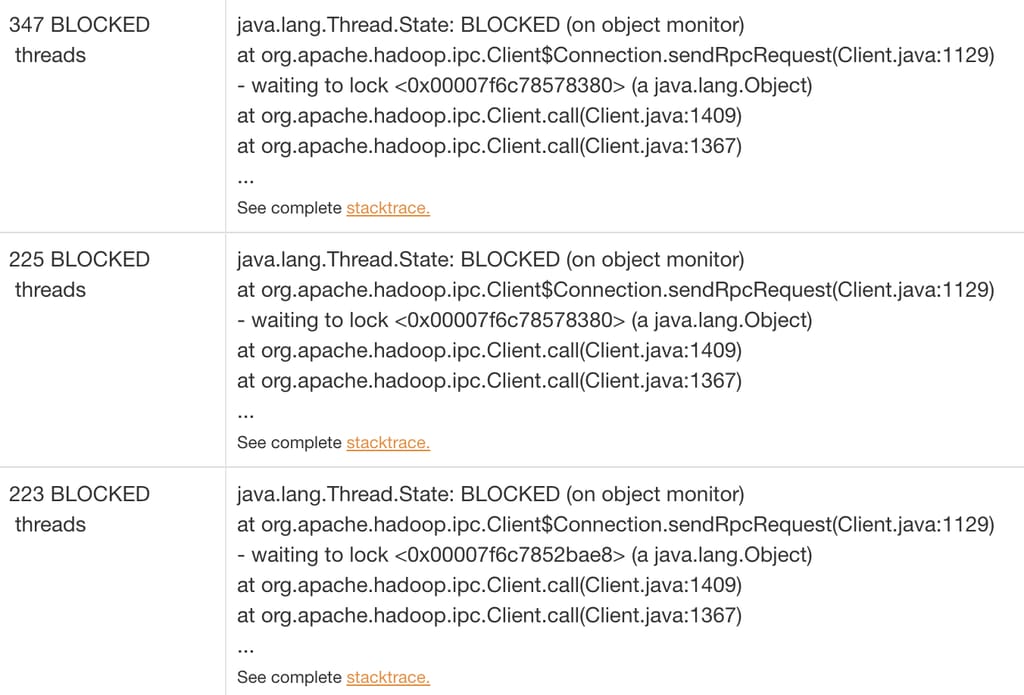
图 5:线程阻塞在 RPC 调用上。
在典型的 Distcp 提交流程中,多个组件依赖 HDFS 客户端:Distcp Worker 用于数据比较,Distcp 工具用于拷贝清单,Hadoop 客户端用于输入分片。随着 Distcp 执行线程数量的增加,并行使用 HDFS 客户端的数量也随之增加。
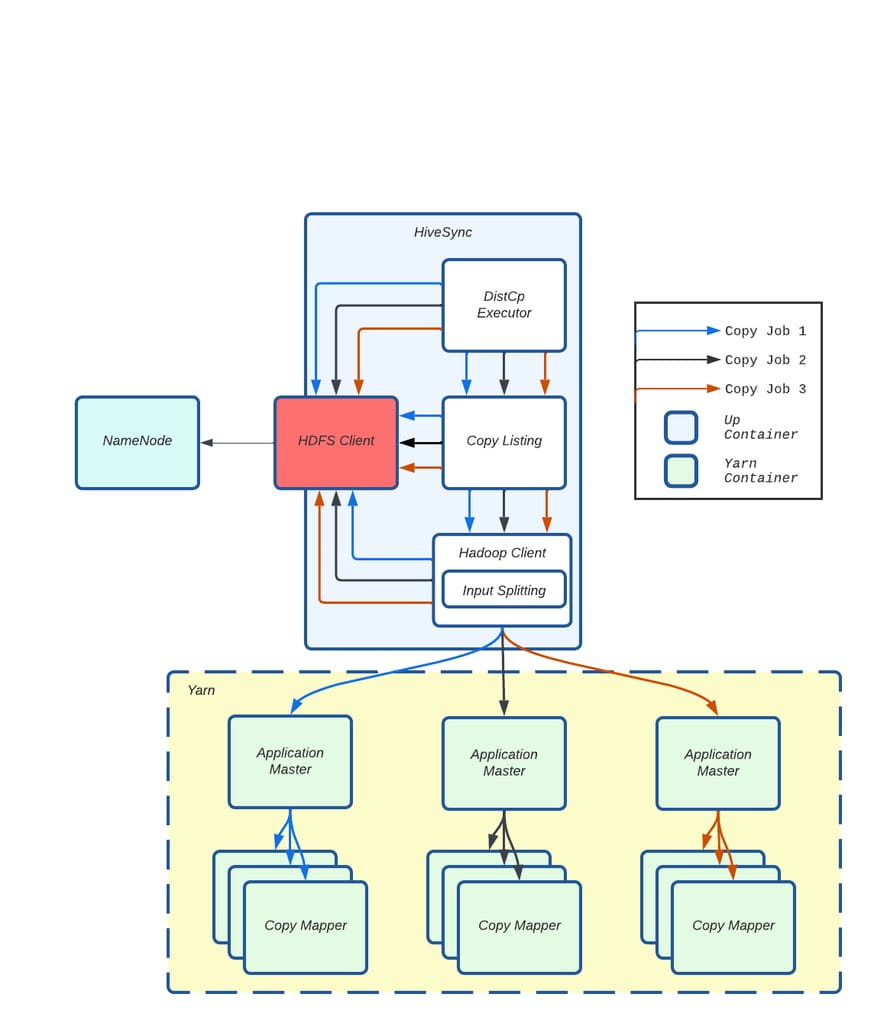
图 6:来自不同拷贝作业请求的多个并行调用在 HDFS 客户端上产生争用。
我们发现,虽然 Distcp 能很好地扩展数据拷贝,但它也在客户端处理文件规划和清单任务。这一准备阶段——识别待拷贝文件(输入分片)——造成了瓶颈,因为它依赖共享的 HDFS 客户端,而该客户端也被 HiveSync 的其他组件使用。随着数据量和 Distcp Worker 数量的增长,HDFS 客户端中的 JVM 级锁成为主要问题,随着并行度的增加导致线程争用。这造成了延迟,其中仅拷贝清单就占了作业提交延迟的 90%。
大量的 NameNode 调用使问题更加严重,这些调用与待拷贝文件数量成正比——对于大型目录尤为突出。
为了减轻单个 HDFS 客户端的负载,我们将资源密集型的拷贝清单和输入分片任务从 HiveSync 服务器转移到了 AM。
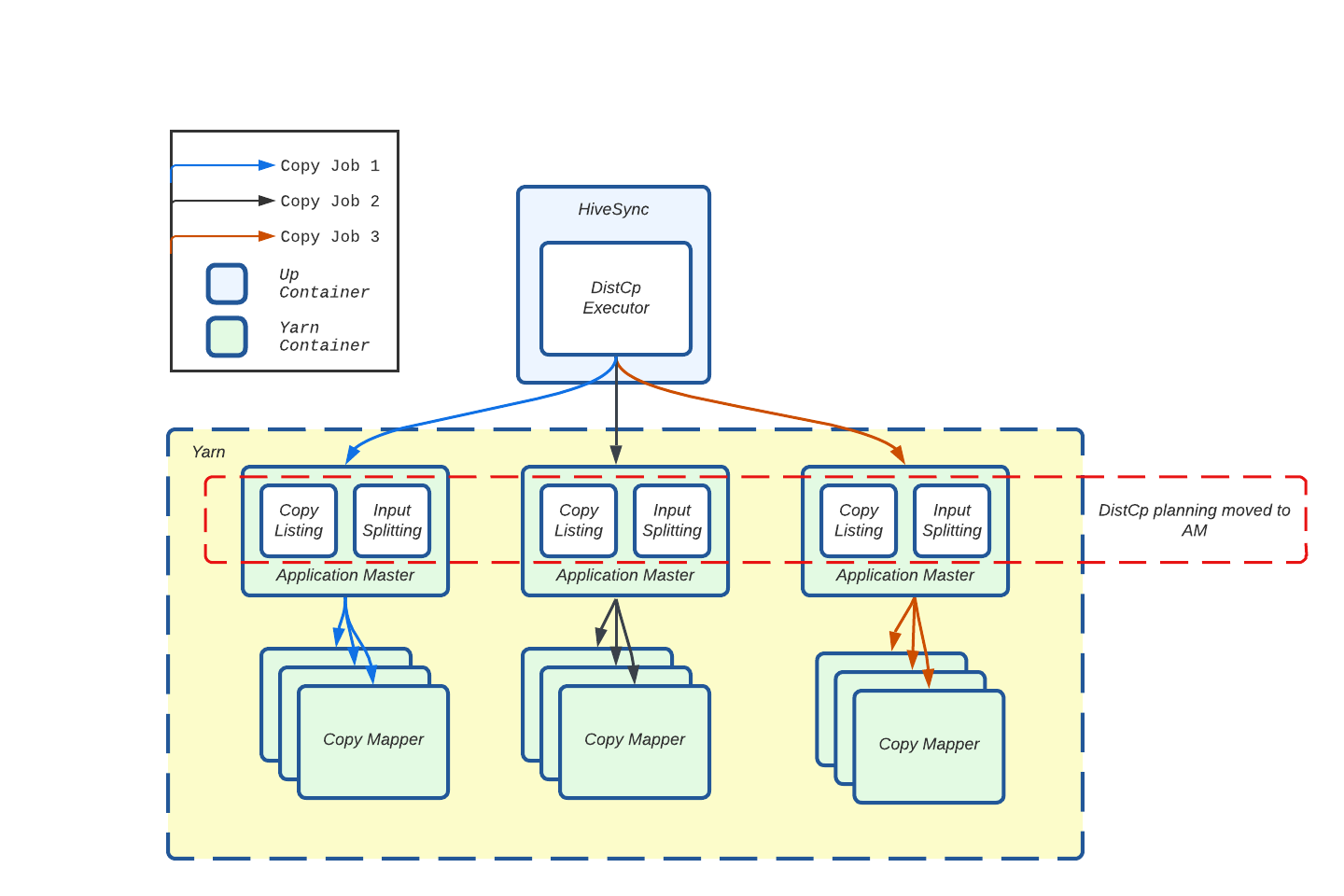
图 7:将拷贝清单和输入分片流程从 Hive Sync 服务器(客户端)转移到 AM。
现在,每个 Distcp 作业在自己的 AM 容器中执行拷贝清单,这显著减少了 HiveSync Hadoop 客户端上的锁争用。这帮助我们实现了 Distcp 作业提交延迟 90% 的降低。
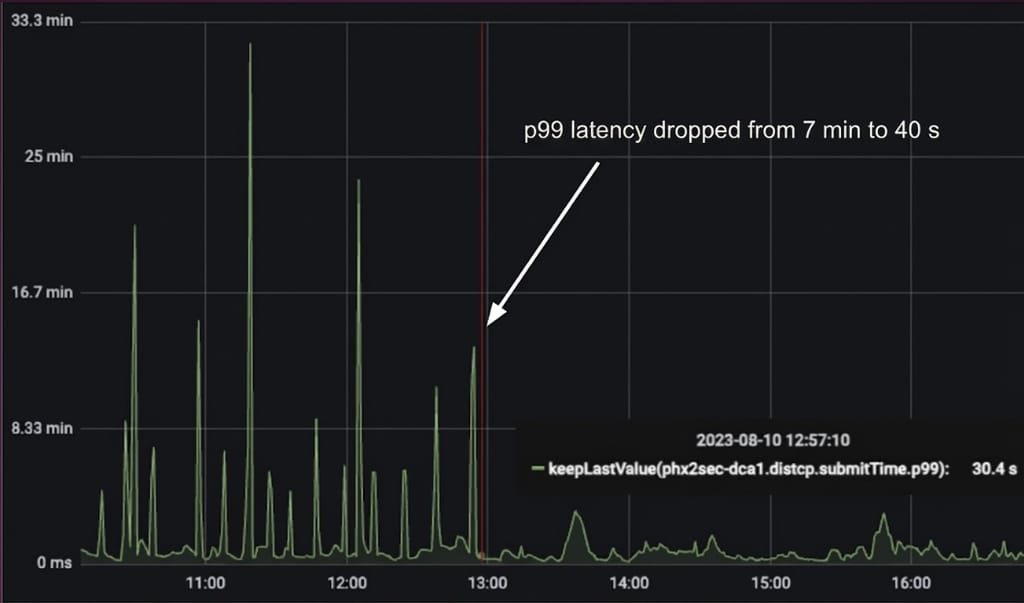
图 8:观测到 Distcp 作业提交时间降低了 90%。
并行化拷贝清单任务
Distcp 工具运行拷贝清单任务以生成待拷贝文件的文件系统块。这些块被写入序列文件(Sequence File),形成一个文件块列表,供拷贝映射器任务从源集群复制到目标集群。在此过程中,主线程通过 getFileBlockLocations API 依次调用 NameNode,为超过指定块大小的文件创建文件分片(Chunk)。它还在文件状态检查失败时进行重试,使这成为 Distcp 中最耗费资源的部分。
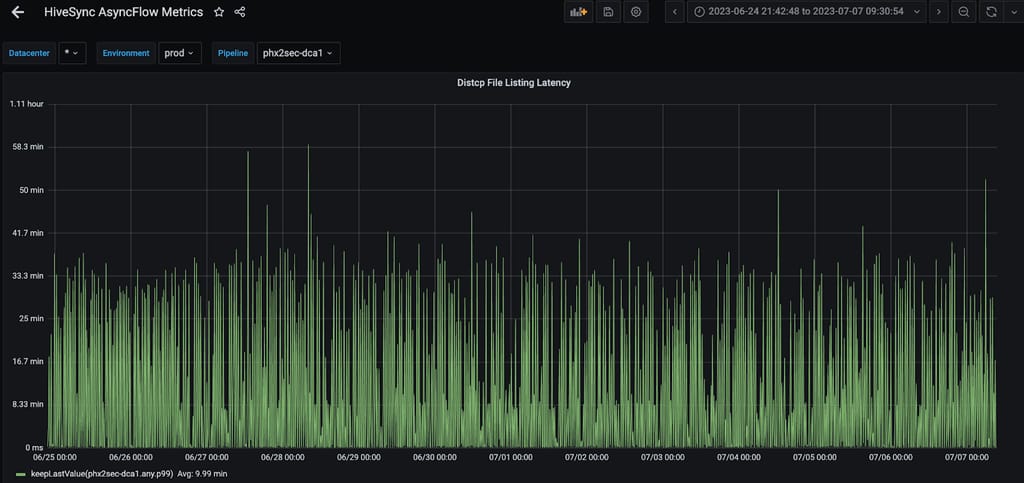
图 9:即使将此任务移至应用主节点后,最繁忙的复制服务器上 P99 延迟平均仍约 10 分钟。
我们观察到多个文件可以并行列出,并以任意顺序写入序列文件。但是,每个文件的块需要保持在一起并按顺序排列,因为拷贝提交器算法使用它们在目标端合并已拷贝的文件分片。基于这一思路,我们通过为每个文件分配单独的线程来创建分片,将文件系统 NameNode 调用并行化以降低拷贝清单延迟,将分片添加到阻塞队列中,由单独的写入线程按顺序将块写入序列文件。这一方法帮助改善了 Distcp 作业的完成时间。
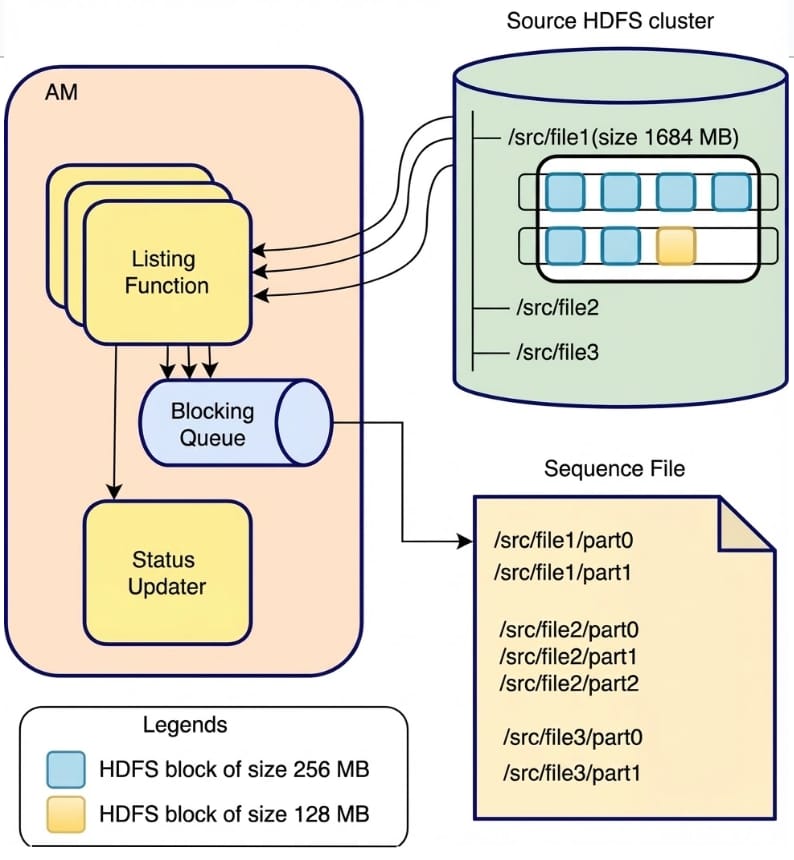
图 10:拷贝清单任务 V2 工作流。
在图 10 中,列出函数使用多线程通过 NameNode 调用从源集群检索文件。每个线程负责为一个文件创建块,允许多个文件的并行处理。例如,/src/file1(1684 MB)被分成两个块:第一个块(/src/file1/part0)包含 4 个 256 MB 的 HDFS 块,第二个块(/src/file1/part1)包含 3 个块(2 个 256 MB 和 1 个 128 MB)。列出线程同步地将这些块添加到阻塞队列中,而单独的写入线程定期轮询队列并按顺序将两个块写入序列文件。为实现快速故障处理,如果任何线程失败,主线程将停止处理并重试 Distcp 作业。列出函数完成且队列中所有项目均已写入序列文件后,它通过状态更新器更新作业状态。
通过使用 6 个线程,我们在所有 HiveSync 服务器上实现了 P99 平均 Distcp 清单延迟降低 60%,最大延迟降低 75%。
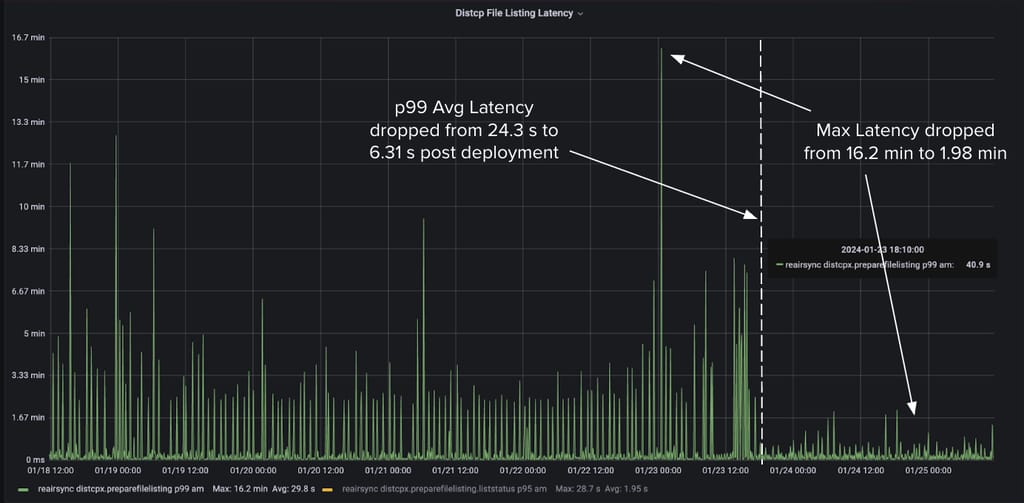
图 11:使用 6 个线程后,某 Hive Sync 服务器上拷贝清单延迟的改善。
并行化拷贝提交器任务
在 Distcp 拷贝映射器任务完成从源目录到目标目录的文件分片拷贝后,AM 中的拷贝提交器任务将这些分片合并为完整文件。对于包含超过 500,000 个文件的目录,这一过程可能需要长达 30 分钟。开源版本按顺序合并文件块,导致性能较低。
为解决这一问题,我们将文件拼接过程并行化,每个线程负责一次合并一个文件。拷贝清单过程中创建的序列文件用于确定需要在目标端合并的各个文件块的顺序。
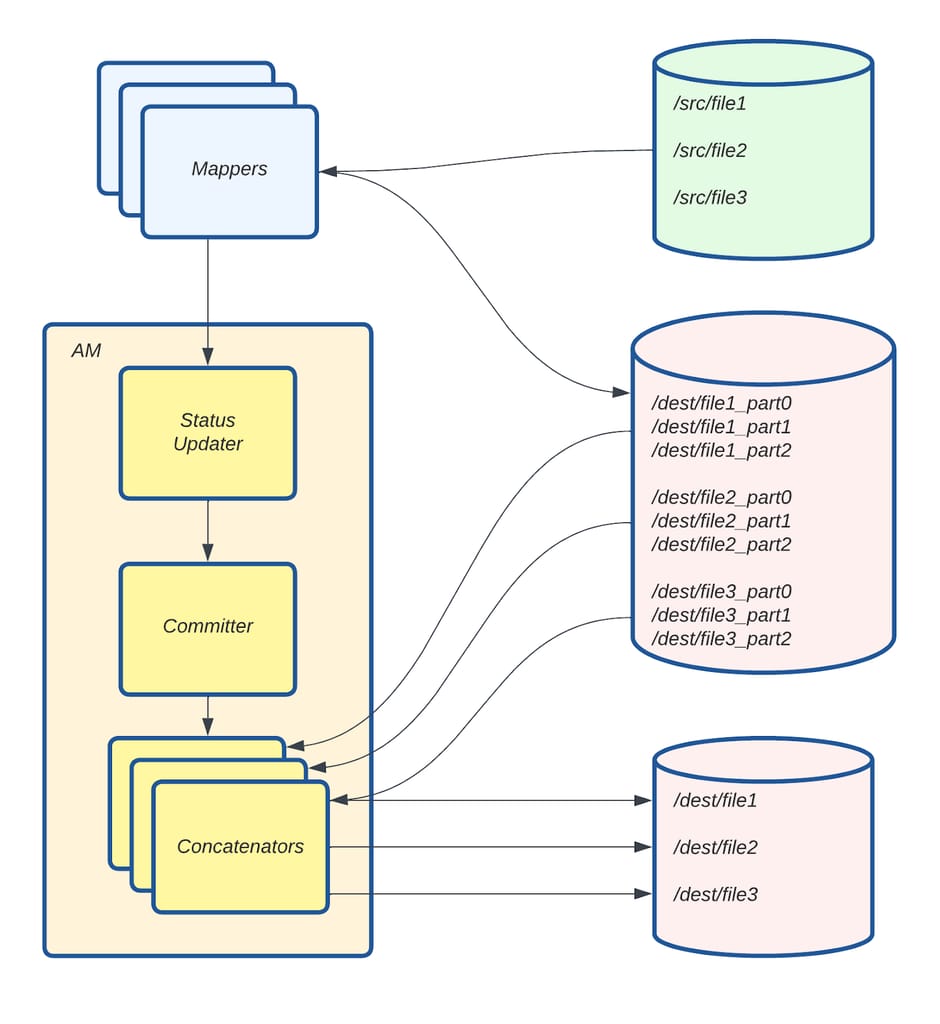
图 12:拷贝提交器任务 V2 工作流。
在图 12 中,Mapper 从序列文件中获取拷贝清单过程中创建的文件分片,并将其拷贝到 /dest/ 下的目标目录。每个拼接线程(Concatenator)收集特定文件的分片并将其合并以创建最终文件。File 1 的三个分片(/dest/file_part0、/dest/file_part1 和 /dest/file_part2)被合并为目标端的 /dest/file1。File 2 和 File 3 同理。为实现快速故障处理,如果任何线程遇到问题,主线程将停止处理并重试 Distcp 作业。
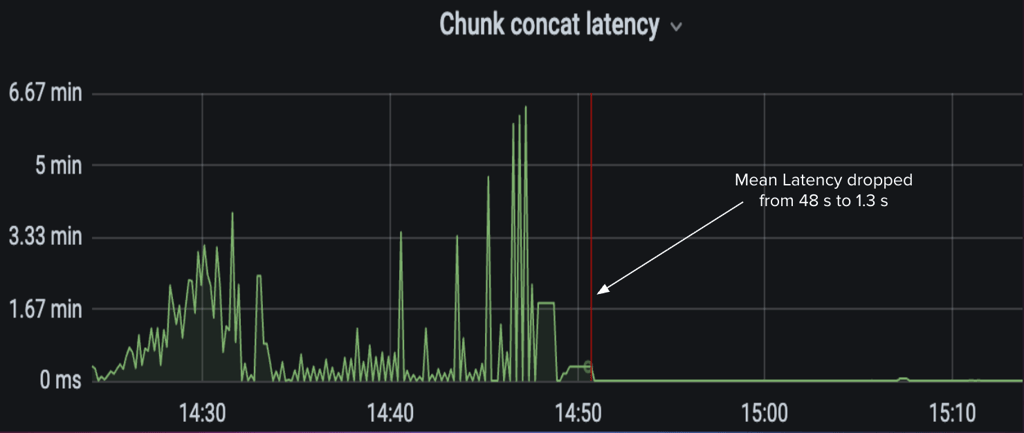
图 13:使用 10 个线程后,平均拼接延迟降低了 97.29%。
Uber 化单 Mapper 作业:改善 YARN 使用效率
约 52% 的 HiveSync 服务器提交的 Distcp 作业仅需一个 Mapper 即可拷贝少于 512 MB 和不到 200 个文件的数据。虽然这些小作业执行速度很快,但大量时间花在了环境设置(在 YARN 中分配新容器和 JVM 启动时间)而非实际拷贝上。
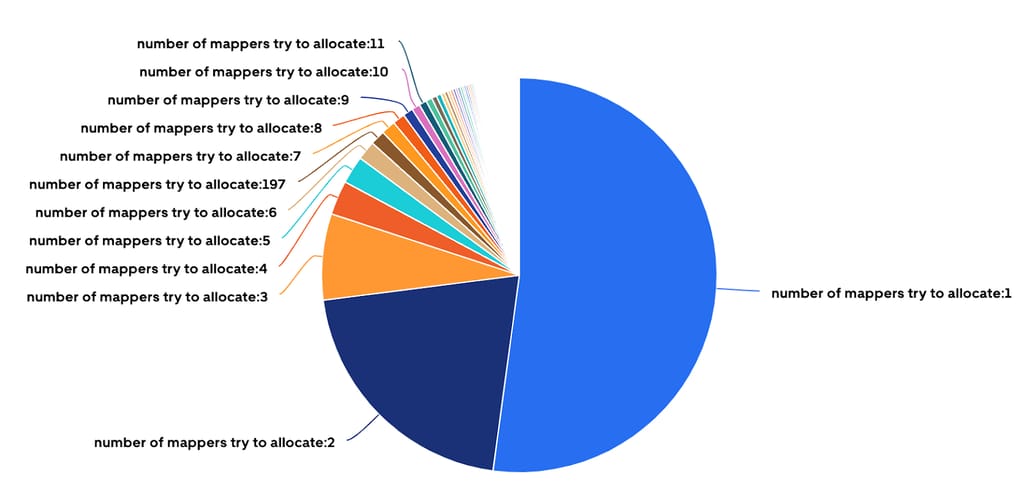
图 14:超过 50% 的 Distcp 作业仅分配了一个 Mapper。
为解决这一开销问题,我们利用了 Hadoop 的 “Uber 作业” 功能,消除了在单独容器中分配和运行任务的需要。拷贝映射器任务直接在应用主节点的 JVM 中执行,减少了不必要的容器分配。
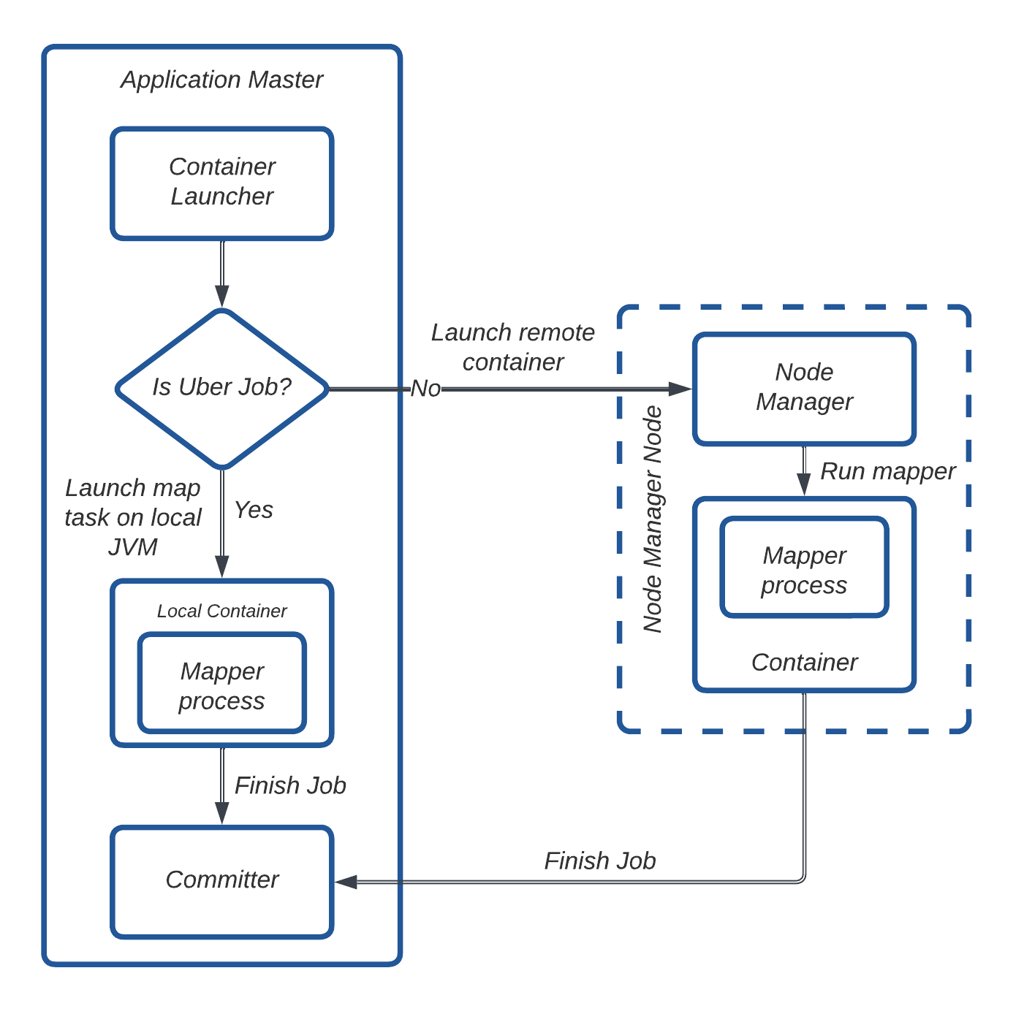
图 15:Uber 作业工作流。
在图 15 中,AM 判断一个作业是否符合 Uber 作业的条件。如果符合,拷贝映射器任务将在 AM 的 JVM 中本地执行。否则,AM 通过 Node Manager 请求容器并在其中运行拷贝映射器任务。任务完成后,AM 启动拷贝提交器任务以在目标端合并文件分片。
我们通过以下配置启用了 Uber 作业:
- mapreduce.job.ubertask.enable: true
- mapreduce.job.ubertask.maxmaps: 1(确保仅使用 1 个 Mapper)
- mapreduce.job.ubertask.maxbytes: 512 MB(限制数据拷贝量为 512 MB)
通过实施这一方案,我们每天减少了约 268,000 次单核容器启动,显著改善了 YARN 资源使用和作业效率。
成效
增量数据复制能力显著提升 5 倍
我们对 Uber Distcp 工具所做的改进极大地提升了跨本地和云数据中心的增量数据复制能力。得益于这些变更,我们在仅一年内将本地数据处理能力提升了 5 倍,且未发生任何与扩展相关的故障。
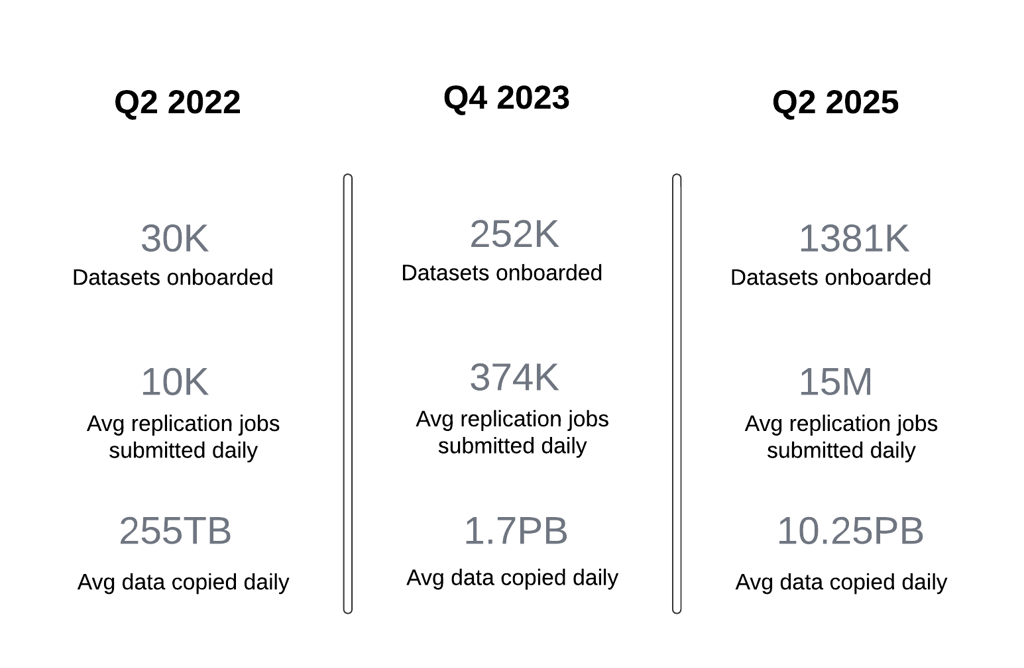
图 16:HiveSync 在本地和云数据中心的规模。
从本地到云的无缝批量数据迁移
近几个月,我们扩展了 HiveSync 的功能以支持将本地数据湖复制到基于云的数据湖,详情见此文。对 Distcp 的增强在处理此次迁移的规模方面发挥了关键作用。截至目前,我们已成功将超过 306 PB 的数据迁移到云端。
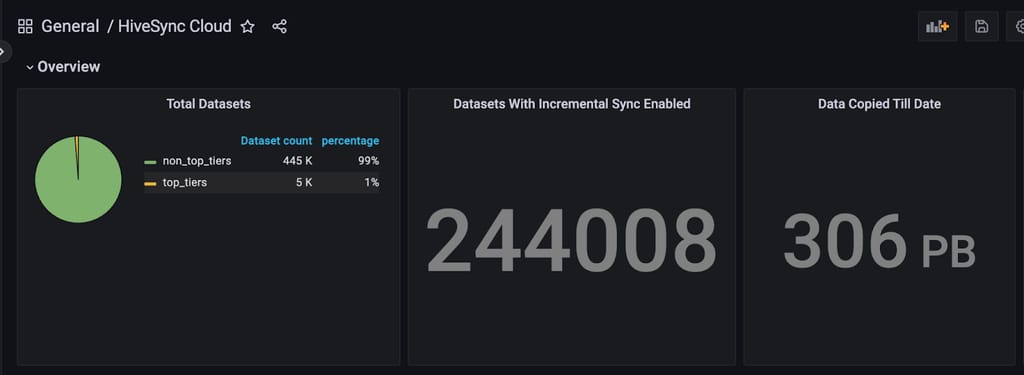
图 17:通过 HiveSync 服务从本地迁移到云端的数据量。
更好的可观测性
我们引入了多个关键指标,显著提升了可观测性(Observability)。这些指标提供了关于客户端和 YARN AM 端 Distcp 作业提交时间、作业提交速率以及关键 Distcp 组件(如拷贝清单和拷贝提交器任务)性能的洞察。我们还跟踪了 Hadoop 容器的最大堆内存使用量、每个作业的 P99 Distcp 拷贝速率以及整体拷贝速率等指标。这种增强的可见性使我们能够更好地监控和了解服务的复制速率,并在缓解和诊断多起故障中发挥了关键作用。
挑战
在将变更部署到生产服务器的过程中,我们面临了几项挑战。其中一个挑战是 AM 中的 OOM(Out of Memory,内存溢出)异常。严格的压力测试帮助我们确定了最优的内存和核心使用配置。我们添加了指标来检测 OOM 问题,这在后续帮助我们为内存密集型拷贝请求确定最优的 YARN 资源配置。
另一个问题是 HiveSync 的高作业提交速率。降低提交延迟提高了作业提交速率,但这经常导致"YARN 队列已满"错误。为防止 YARN 过载,我们在 HiveSync 中实现了熔断器(Circuit Breaker),在重试成功之前暂时暂停新的提交。我们添加了指标来检测此类事件,从而实现实时监控并按需调整 YARN 队列容量。管理高拷贝速率虽然高效,但会导致高网络带宽使用,需要仔细调优以平衡性能和资源限制。
我们还遇到了因长时间运行的拷贝清单任务导致的 AM 故障。最初,拷贝清单和输入分片部分被移至 AM 的启动阶段。这导致了问题,因为 RM 期望 AM 发送定期心跳信号。由于心跳发送器仅在启动完成后才启动,而拷贝清单任务有时需要超过 10 分钟,因此会导致超时。为解决这一问题,拷贝清单任务被移至输出提交器的设置阶段,该阶段在心跳发送器已启动之后执行,从而避免了超时。
结论
展望未来,团队正聚焦于围绕并行化、更好的资源利用和网络管理的若干增强,包括:
- 并行化文件权限设置
- 并行化输入分片
- 将计算密集型提交任务移至 Reduce 阶段以提高可扩展性
- 实现动态带宽限流器
此外,我们计划为这些优化贡献开源补丁。Uber HiveSync 团队将继续专注于解决数据复制挑战,在我们的规模下,即使是微小的改进也能带来显著的收益。