2022年,字节跳动给Golang提了issue建议把map的底层实现改成SwissTable的。2023年,dolt写了一篇博客SwissMap: A smaller, faster Golang Hash Table 分享他们 设计了一个基于SwissTable 的 Map ,引起了广泛的关注。目前 Go 核心团队已经开始重新审视 swisstable 设计,在runtime中也添加了部分代码,趁着假期,刚好有时间深入了解一下原理,跟runtime map 相比有什么区别,以及为什么它可能会成为map的标准实现。
This article was first published in the Medium MPP plan. If you are a Medium user, please follow me on Medium. Thank you very much.
本文不会完全解释hashtable或者swisstable的原理。您需要对hashtable 有一定的了解。
哈希表提供了一个key到对应value的映射,通过一个hash函数把key转换成某个“位置“,从这个位置上可以直接拿到我们想要的value,
传统 hashtable
哈希表提供了一个key到对应value的映射,通过一个hash函数把key转换成某个“位置“,从这个位置上可以直接拿到我们想要的value。不过,即使hash函数再完美,把无限的key映射到一个有限大小的内存空间内也还是不可避免得会产生冲突:两个不同的key会被映射到同一个位置。 为了解决这个问题,传统的hashtable有好几个解决方案,最常见的解决冲突的办法有“链表法”和“线性探测法”。
链表法
链表法是最常见的,它的中心思想在于如果key映射到了相同的位置,那么就把这些key和value存在一张链表里。查找的时候先用hash函数计算得到位置,然后再从存放在该位置上的链表里一个个遍历找到key相等的条目。它的结构类似这样:
figure 1: 拉链法实现 hashtable
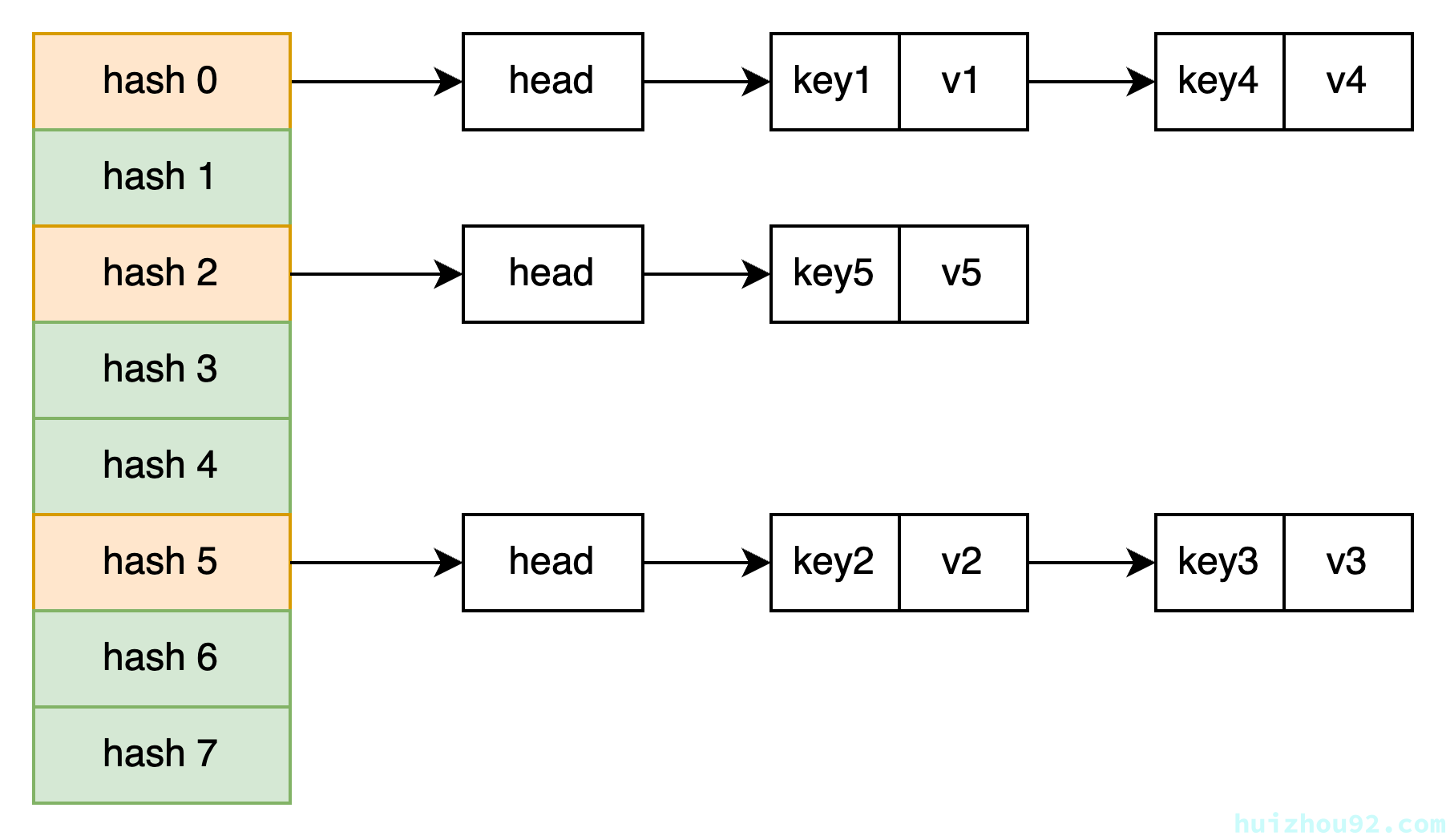
链表法实现很简单,没那么多边界条件要考虑,插入数据和删除数据很快,插入用链表的头插法,删除只需要移动部分节点的next指针。此外,链表法能采取扩容之外的手段阻止查询性能退化,比如把过长链表转换成搜索树等。链表法的缺点是本身对缓存不够友好,冲突较多的时候缓存命中率较低从而影响性能。不同的slot之间数据在内存里的跨度较大,数据结构整体的空间局部性较差。
线性探测法
线性探测是另一种常见的哈希表冲突解决方法。它解决冲突的方式于链表法不同,在遇到hash冲突的时候,它会从冲突的位置开始向后一个个查找,直到找到一个空位,或者没找到然后索引回到了冲突发生的位置,这时会进行扩容然后再重新执行上述插入流程。
Figure 2 :线性探测法添加数据 动画演示

查找也是一样的,首先通过hash函数计算得到元素应该在的位置,然后从这个位置开始一个个比较key是否相等,遇到被删除的元素就跳过,遇到空的slot就停止搜索,这表示元素不在这个哈希表中。所以删除元素的时候,使用的是标记删除。
Figure 3: 线性探测法查找数据演示
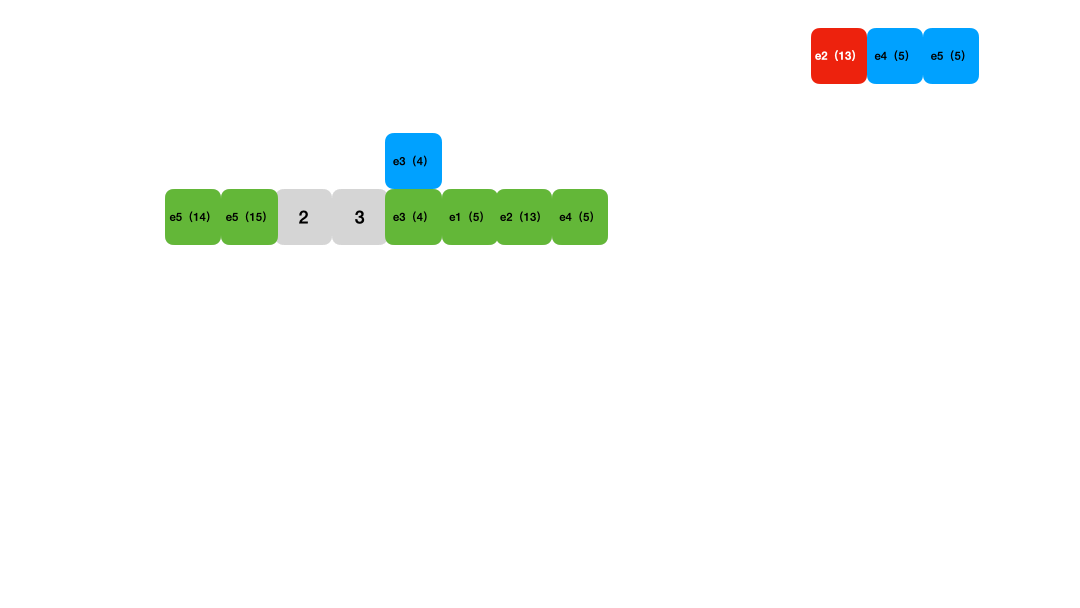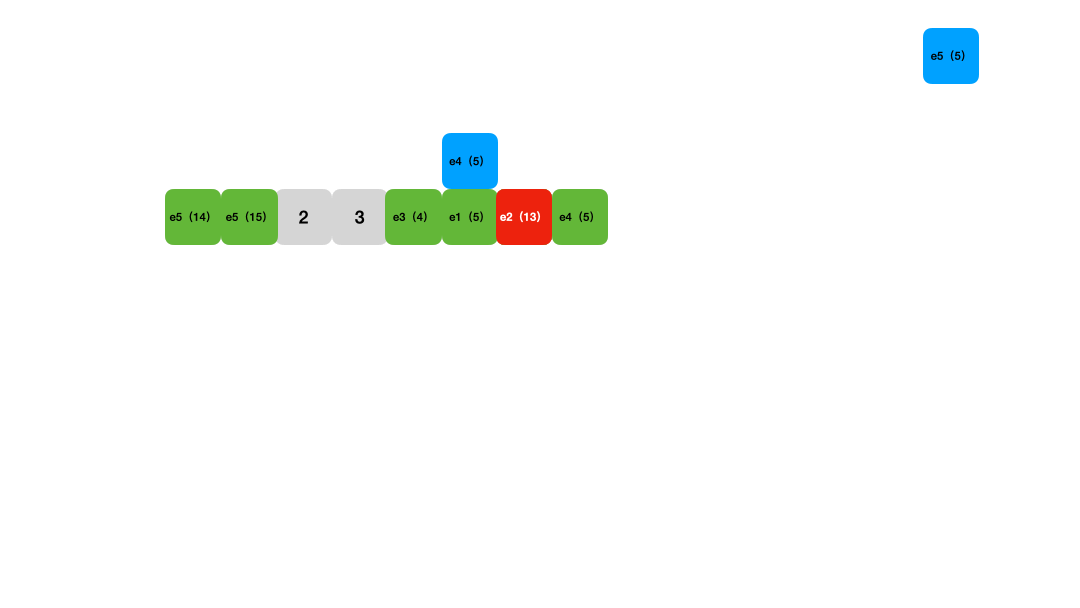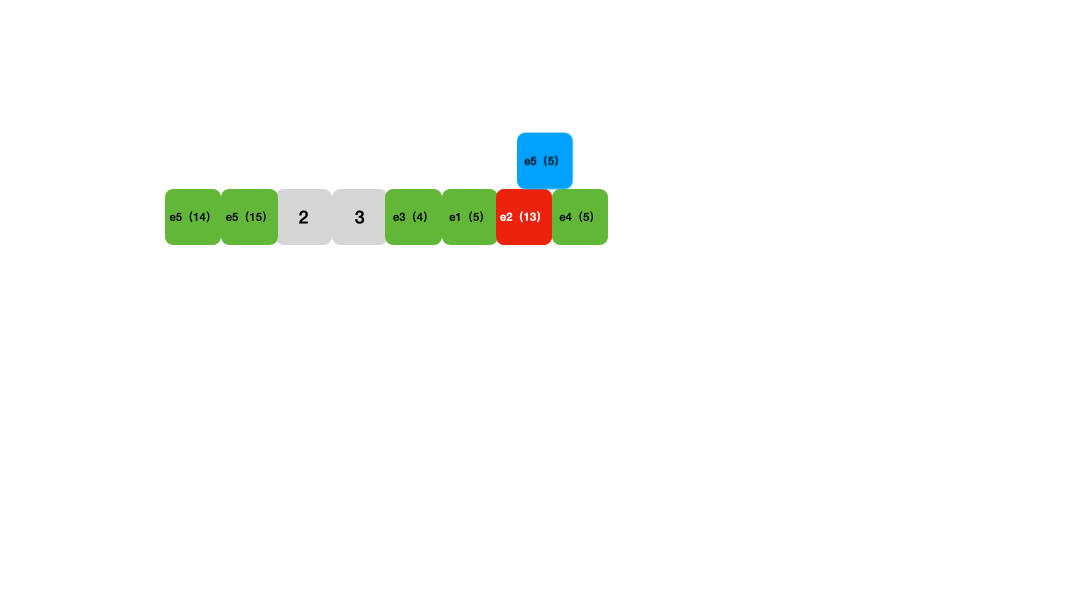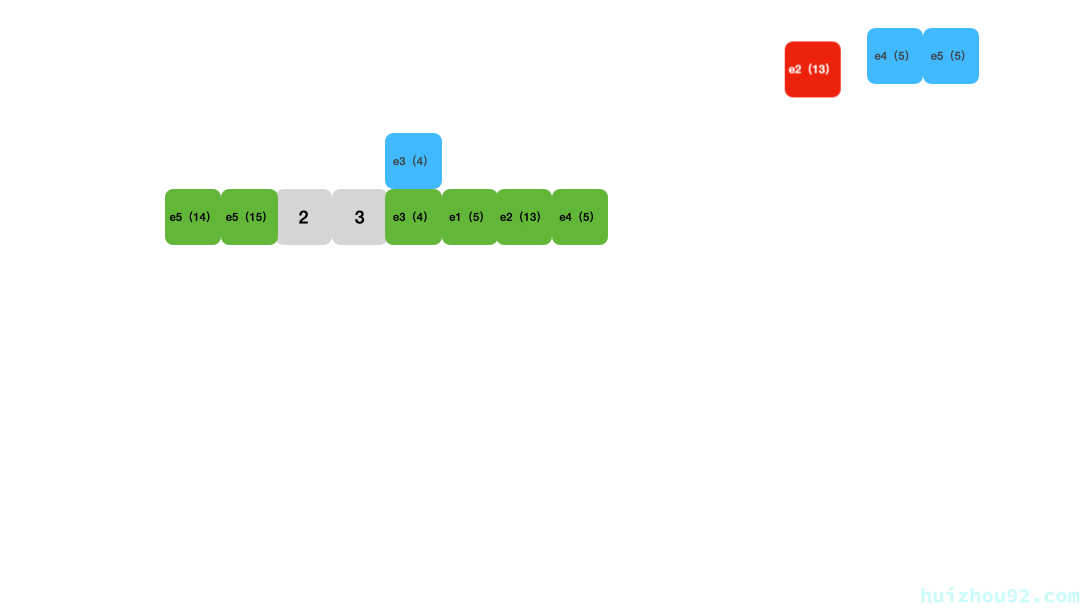
线性探测法 的时间复杂度跟链表法差不多,它的优点是对缓存友好,现在可以用数组之类的紧密数据结构实现。同时,它的缺点也很明显:
- 实现复杂,一个
slot有元素、空、被删除这三种状态 - hash冲突是连锁式的,一处冲突可能会连续影响多处,最终导致插入同样的数据,它扩容的次数会比链表法更多,最终可能会用掉更多的内存。
- 因为冲突会造成后续插入和删除的连锁反应,所以查找过程退化到
O(n)的概率更大,而且没法像链表法那样把有大量冲突的地方转换成搜索树之类的结构。
因为删除元素麻烦,加上冲突会有连锁影响,所以很多库实现的hashtable都是用的链表法。不过即使有这么多缺点,光缓存友好和内存利用率高在现代计算机上就是非常大的性能优势了,所以像golang和python都会使用线性探测法的近似变种来实现哈希表。
Go Hashmap 如何存储数据
我们首先来回忆一下 Go Map 是如何存储数据的。
figure 4: go map 示意图
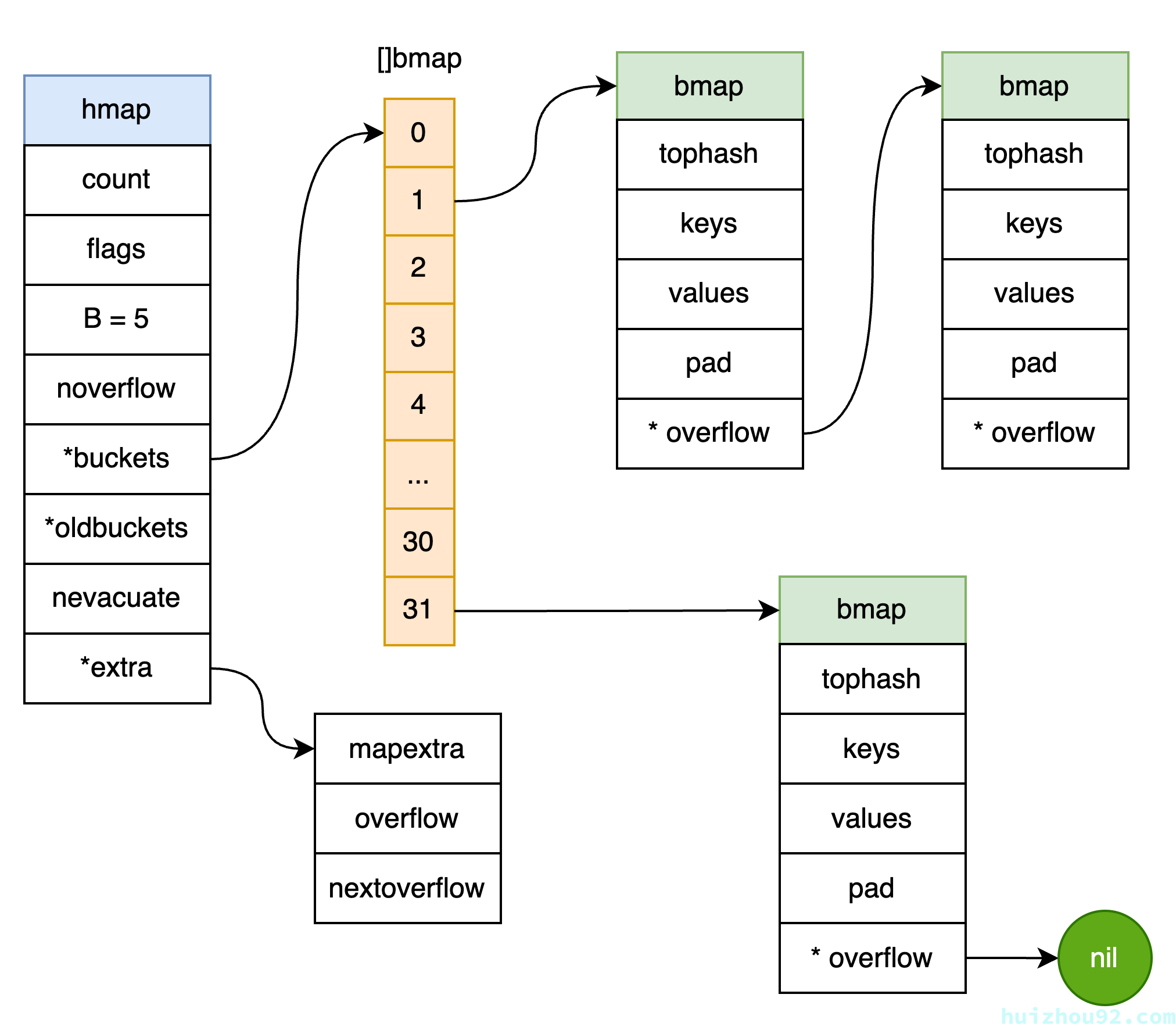
快速总结一下:
- Go
map底层通过哈希函数将 key 映射到多个bucket中。每个bucket具有固定数量的键值对slot,用于存储 key 和对应的 value。 - 每个
bucket能存储 8个键值对。当冲突发生时(即多个 key 被映射到同一个bucket),这些 key 和 value 会在同一个bucket内存储。 map通过哈希函数计算 key 的哈希值,并根据哈希值找到对应的bucket。- 如果某个
bucket被填满(8 个slot已用完),会生成一个overflow bucket,继续存储新的键值对。 - 查找时数据时,首先计算要查找的 key 的哈希值,然后确定该哈希值映射到的
bucket。Go 会检查每个slot,如果bucket中存在overflow bucket,会顺序检查overflow bucket中的 key。
SwissTable,一种高效的 hashtable 实现方式
SwissTable 是一种基于改进的线性探测法的哈希表实现,其核心思想是通过改进哈希表的结构和元数据存储,优化了性能和内存使用。SwissTable 采用了一种新的元数据控制机制,大幅减少了不必要的键比较操作,同时利用 SIMD 指令提升吞吐量。
我们回顾了一下两种常见的哈希表实现,它们要么浪费内存且对缓存不友好;要么发生冲突后会更容易导致查找、插入、删除操作性能下降。这还是在有“完美哈希函数”的情况下,如果你用了个不那么好的哈希函数,那会导致key冲突的概率大大上升,性能问题会更加明显,最坏的情况下性能甚至会不如在数组里进行线性搜索。
业界开始寻找一种既对缓存友好又不会让查找性能退化的太厉害的哈希表算法。大多数人的研究方向是开发更好的哈希函数,在让哈希函数不断接近“完美哈希函数”的品质的同时用各种手段优化计算性能;另外一些人在改进哈希表本身的结构力求在缓存友好、性能和内存用量上找到平衡。swisstable就属于后者。
swisstable的时间复杂度和线性探测法的差不多,空间复杂度介于链表法和线性探测之间。 swisstable的实现有很多,我主要基于dolthub/swiss这个实现进行简要的介绍。
SwissTable 的基本结构
虽然名字变了,实际上swisstable依然是hashtable,而且使用改进的线性探测法来解决hash冲突。 所以大家应该能想象到,swisstable的底层应该也是个类似数组的结构。有了这样大致的模糊印象就可以了,现在我们可以来看看swisstable的结构了:
|
|
在swisstable 的实现中,ctrl 是一个 []metadata ,[]metadata 跟 []group[K, V] 数量对应 。每个group有8个slot
hash会被分成两部分:57bits长度的为H1,用于确定从哪个groups开始探测,剩下的7bits叫做H2,刚好放在metadata中, 被用作是当前key的哈希特征值,用于后面的查找和过滤。
swisstable比传统哈希表更快的秘诀就在于这些被叫做ctrl的metadata。控制信息主要是下面这几种:
- slot是否为空:
0b10000000 - slot里的元素是否已经被删除:
0b11111110 - slot里存的键值对的key的哈希特征(H2)
0bh2
对于空、删除这几种特殊状态,对应的值都是特意设置的,目的是为了能够在后面的匹配中使用SIMD指令,获得最高的性能。
查找、插入、删除都是基于这些ctrl的,它们非常小,可以尽量多的被放入CPU的高速缓存,同时又包含了足够的信息以满足哈希表的增删改查。而slot就只用来存数据,ctrl和slot一一对应,控制信息在ctrl里的索引就是对应的数据在slot里的索引,下面以添加数据为例,查找,删除 都差不多。
添加数据
swisstable 添加数据的过程分成几个步骤。
- 计算哈希值并分割为
h1和h2, 根据h1确定开始探测的groups, - 使用
metaMatchH2检查当前组中的metadata是否有匹配的h2。如果找到匹配的h2,则进一步检查对应槽位中的键是否与目标键相同。如果相同,则更新值并返回。 - 如果没有找到匹配的键,使用
metaMatchEmpty检查当前组中是否有空闲slot。如果有slot,则插入新的键值对,并更新metadata和resident计数。 - 如果当前组没有空闲槽位,进行线性探测,检查下一个
groups。
|
|
虽然,步骤很少,但是里面使用了比较复杂的位运算,按照正常的流程,需要把h2 跟所有的 对比,直到找到我们要的目标。swisstable 使用了一个很巧妙的方式来实现这个目标。
- 首先将
h2 * 0x0101010101010101得到一个uint64,这样就能一次性对比 8个ctrl - 然后跟
meta做 xor 运行。 如果h2存在于metadata中。那么对应的bit 就是0b00000000,metaMatchH2的作用,可以用 下面的单元测试理解, nextMatch用于确定 key 在group中的的具体位置。
|
|
SwissTable 的优势
看完SwissTable的实现,可以总结为下面几点:
- 对
hashtable的操作从slot转移到了ctrl上,ctrl更小更容易被填入CPU的高速缓存,因此比直接在slot上操作更快,即使需要多付出一次从ctrl得到索引后再去查找slot的代价。 - 记录哈希特征值,减少了无意义的key等值比较,这是线性探测法性能下降的主要元凶。
- 对
slot的查找和操作是通过ctrl批量进行的,单位时间内吞吐量有显著提升。 - 标志位的值和整个数据结构的内存布局都为
SIMD进行了优化,可以充分发挥性能优势。 - 对
slot也有优化,比如对太大的数据会压缩存储以提高缓存命中率。
swisstable解决了空间局部性问题的基础上,还利用了现代CPU的特性批量操作元素,所以性能会有飞跃般的提升。
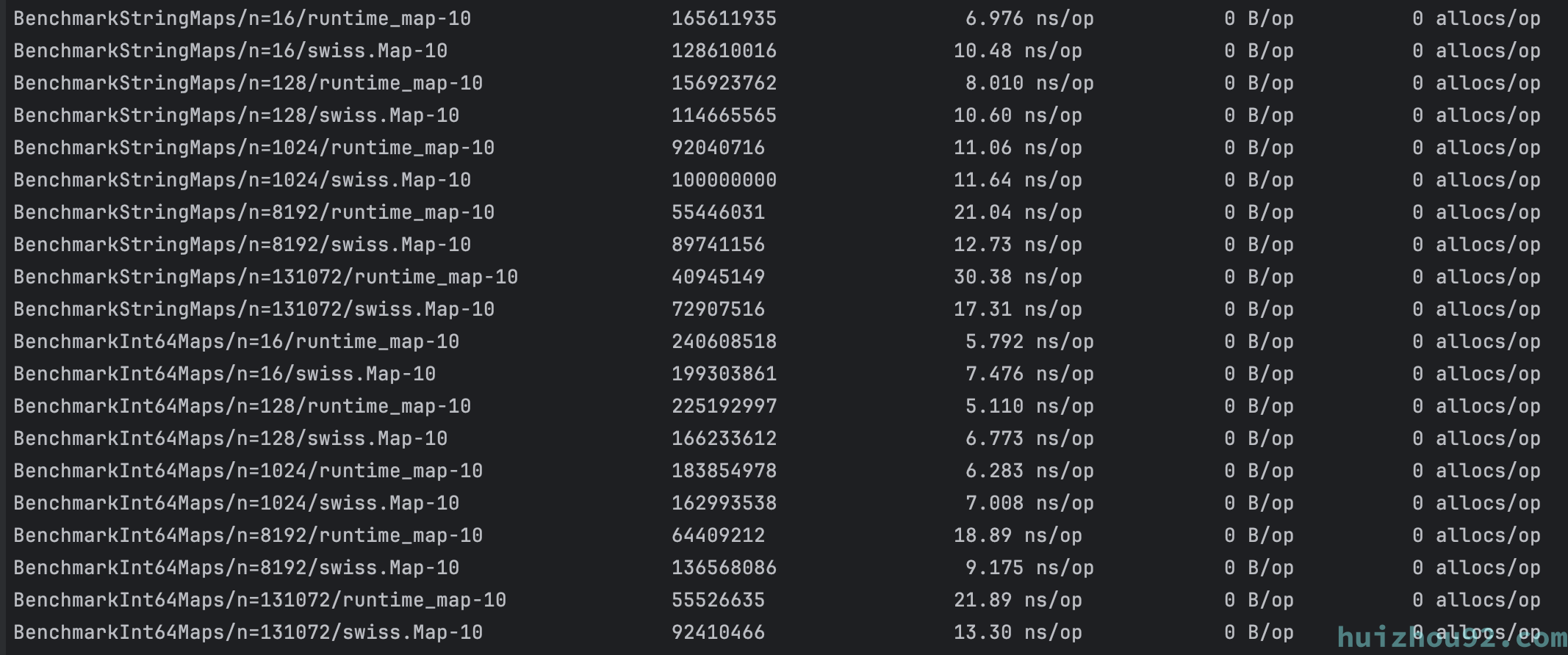
最后在我本地macbook m1 (不支持SIMD)上跑benchmark,结果如下,在大map场景下,swisstable 性能有比较明显的提升。
Figure 5: swisstable 官方benchmark
总结
目前go 官方还没有swisstable 的实现, 但是关于它的讨论一直再继续,目前社区也有几种实现。比如concurrent-swiss-map ,swiss 等。
不过实现都不是特别完美,比如在小map 场景下swisstable 的性能甚至比不上 runtime_map 等。但是swisstable 表现出来的潜力已经在其他语言上的表现,说明它值得我们期待。
参考文档
- dolthub https://www.dolthub.com/blog/2023-03-28-swiss-map/
- swisstable 原理 https://abseil.io/about/design/swisstables
- 首次提出
swisstable的cppcon演讲:https://www.youtube.com/watch?v=ncHmEUmJZf4 - 针对
swisstable算法的一些改进:https://www.youtube.com/watch?v=JZE3_0qvrMg - 位运算原理: http://graphics.stanford.edu/~seander/bithacks.html##ValueInWord
- hash 函数对比: https://aras-p.info/blog/2016/08/09/More-Hash-Function-Tests/
- 另外一篇位运算原理的文章 https://lemire.me/blog/2016/06/27/a-fast-alternative-to-the-modulo-reduction/