
近年来,Go 语言的垃圾回收(GC)机制虽然经历了多个版本优化,但它的性能瓶颈,尤其在高并发与大规模内存场景下,依然是开发者关注的重点。最近,Go 官方在 GitHub 上提出的 Green Tea GC(#73581)引发了热议:它能否进一步解决 Go GC 的耗时问题?本文将深入解析 Go GC 的设计、缺点、实测表现,并带你了解 Green Tea GC 的技术突破。
📦 Go GC 的设计与实现
自 Go 1.5 起,Go 使用并发标记-清除(concurrent mark-sweep)算法,结合“三色标记”模型与 Yuasa 写屏障。
简而言之,Go GC 会在后台并发地遍历堆内存,标记可达对象,并逐步清除未被引用的内存块。整个回收过程中,Go 追求低延迟、低停顿:
✅ 并发标记、并发清除
✅ 不会移动对象(即 no compaction)
✅ 按 span(内存块)分批清扫,减少单次 STW(Stop-the-World)时长
这种设计的直接好处是:应用大部分时间能与 GC 并行工作,最大停顿时间通常低于毫秒级。
🚧 Go GC 的已知问题
虽然 Go GC 的延迟表现优秀,但它在耗时和扩展性上仍有几个硬伤,尤其体现在:
1️⃣ 内存访问低效
GC 的标记阶段会跨对象跳跃,导致 CPU 频繁 cache miss、等待内存,约 35% 的 GC CPU 周期被耗在“等内存”。这在 NUMA 架构或多核大内存机器上尤为明显。
2️⃣ 缺乏分代收集
Go GC 没有分代机制,所有对象一视同仁,这在高分配率场景下显得笨重。Pinterest 工程师曾指出,内存压力一旦增大,GC 就会暴增 CPU 消耗,引发延迟激增。
3️⃣ 频繁 GC 带来的 CPU 占用
Twitch 工程团队曾报告:即便在中小堆内存下(<450 MiB),系统稳态下每秒会触发 8–10 次 GC,每分钟累计 400–600 次,GC 占用约 30% 的 CPU 时间。这直接挤压了业务线程的执行空间。
📊 性能测试:GC 对 Go 程序的影响
我们来看几个实际基准的变化:
- Go 1.3/1.4(并发 GC 前)
大堆(10GB+)上的 GC 停顿:以秒计算。 - Go 1.5(并发 GC 引入后)
相同条件下,GC 停顿压缩到 <1ms。
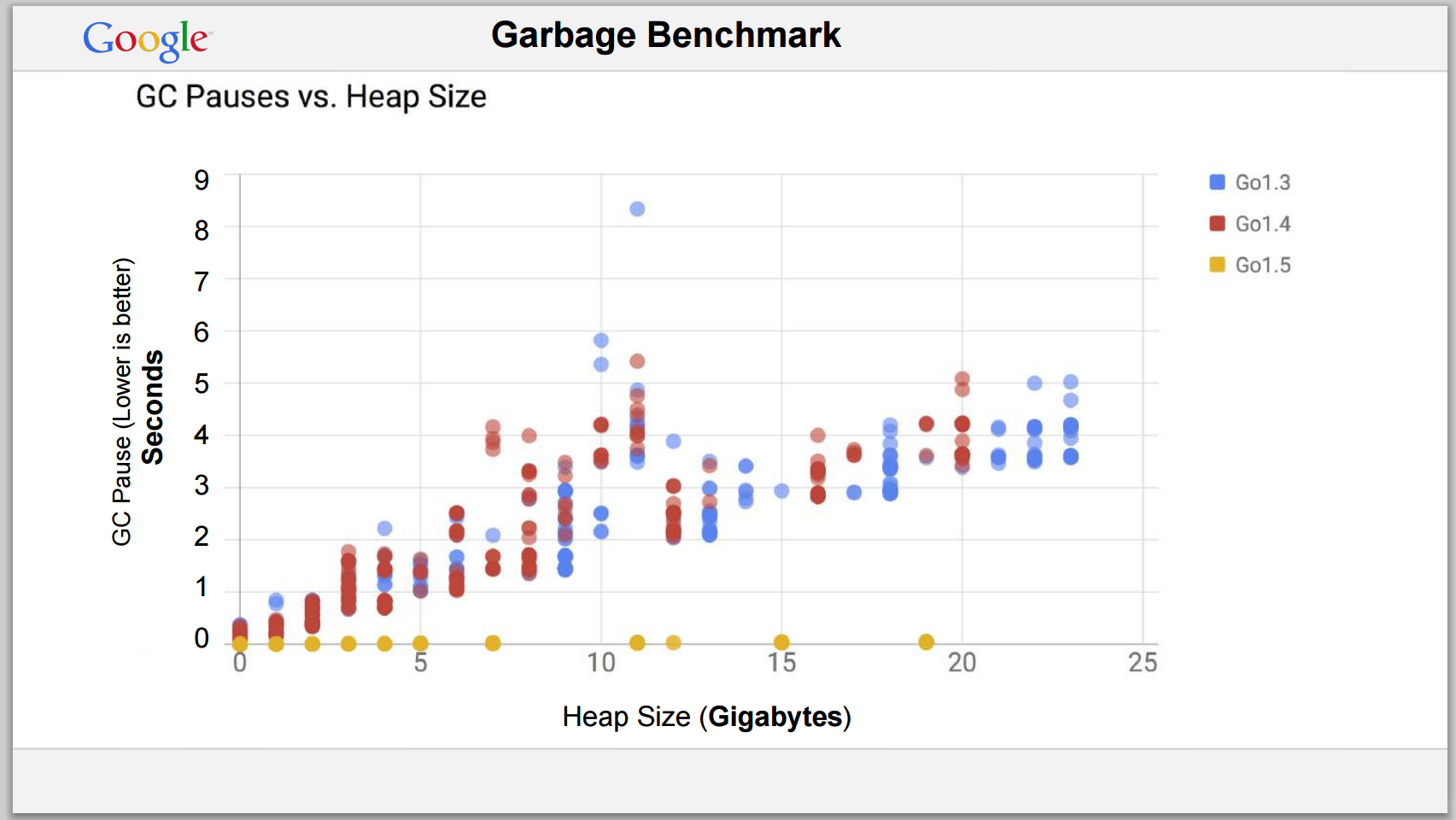
- Go 1.6–1.8
最大堆 200GB,GC 停顿控制在 20ms 以下,甚至常态 1ms。
这些进步非常亮眼,但注意:
✅ 延迟控制好了
⚠️ 总耗时和 CPU 消耗依然显著,特别是高负载或高分配场景。
🌿 Green Tea GC:全新优化方案
面对这些问题,Go 官方提出了 Green Tea GC。它的核心优化点是:
从单对象扫描,升级为按 span(内存块)批量扫描。
具体来说:
- 小对象(≤512B)标记由单个对象粒度提升为 span 粒度。
- 每个 span 中,只有首次标记的对象会将整个 span 推入扫描队列。
- GC 扫描阶段批量处理整个 span,极大提升了内存访问局部性。
此外,Green Tea 改进了并行队列管理,采用类似 Go 调度器的工作窃取机制,进一步提高了多核扩展性。
⚡ Green Tea GC 实测表现
从初步基准来看,Green Tea GC 带来了有选择性的性能提升:
✅ Tile38 基准(高扇出树结构)
- GC 开销降低约 35%
- 吞吐、延迟、内存使用全面优化
⚠ bleve-index 基准(低扇出、频繁变异)
- 对象分布散乱,内存局部性差
- Green Tea 与常规 GC 性能相近,有时略低
总结:Green Tea 并非“银弹”,但在内存局部性良好、多核扩展场景下,它展现了明显优势,并为未来 SIMD 加速等硬件优化奠定了基础。
🏁 总结
| 比较项 | 当前 Go GC | Green Tea GC |
|---|---|---|
| 标记粒度 | 单对象 | span(批量) |
| 内存局部性 | 差,随机跳跃 | 高,同 span 内批量 |
| 多核扩展性 | 受限 | 改进,采用工作窃取队列 |
| 性能提升 | 已接近低延迟上限 | 某些场景下 GC 耗时降 35% |
| 应用适用范围 | 普通场景 | 内存局部性好、分配密集场景 |
对于追求极限性能的开发者,Green Tea GC 提供了一个值得关注的新方向。想要试验 Green Tea,可以在 Go 1.25+ 开启实验标志体验。
📝 参考资料
- GitHub Issue #73581
- https://stackoverflow.com/questions/31684862/how-fast-is-the-go-1-5-gc-with-terabytes-of-ram