背景
Rhys Hiltner 在 2024 年提出了改进互斥锁的性能优化诉求。现在这个优化已经合并到即将发布的Go1.24中,在锁竞争激烈的场景下最多会提升70%的性能。
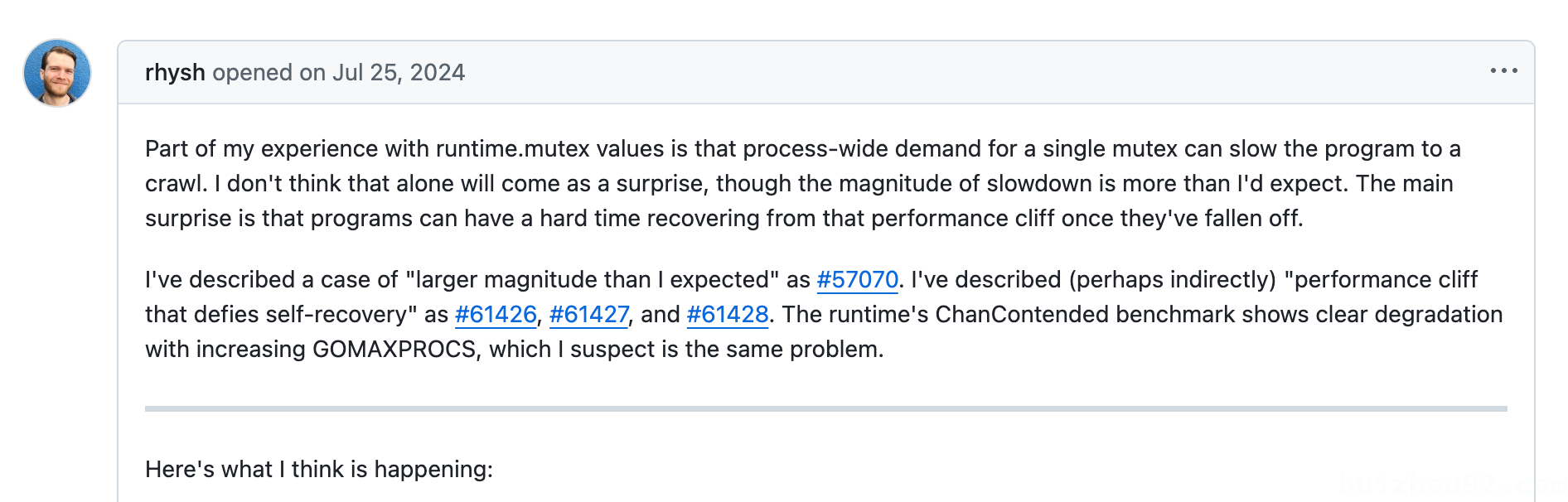
在基准测试 ChanContended 中,作者发现随着 GOMAXPROCS 的增加,mutex 的性能明显下降。
Intel i7-13700H (linux/amd64):
- 当允许使用 4 个线程时,整个进程的吞吐量是单线程时的一半。
- 当允许使用 8 个线程时,吞吐量再次减半。
- 当允许使用 12 个线程时,吞吐量再次减半。
- 在
GOMAXPROCS=20 时,200 次channel操作平均耗时 44 微秒,平均每 220 纳秒调用一次 unlock2,每次都有机会唤醒一个睡眠线程。
另一个角度是考虑进程的 CPU占用时间。
下面的数据显示,在 1.78 秒的Wall-Clock Time内,进程的20个线程在lock2调用中总共有27.74秒处于CPU(自旋)上。
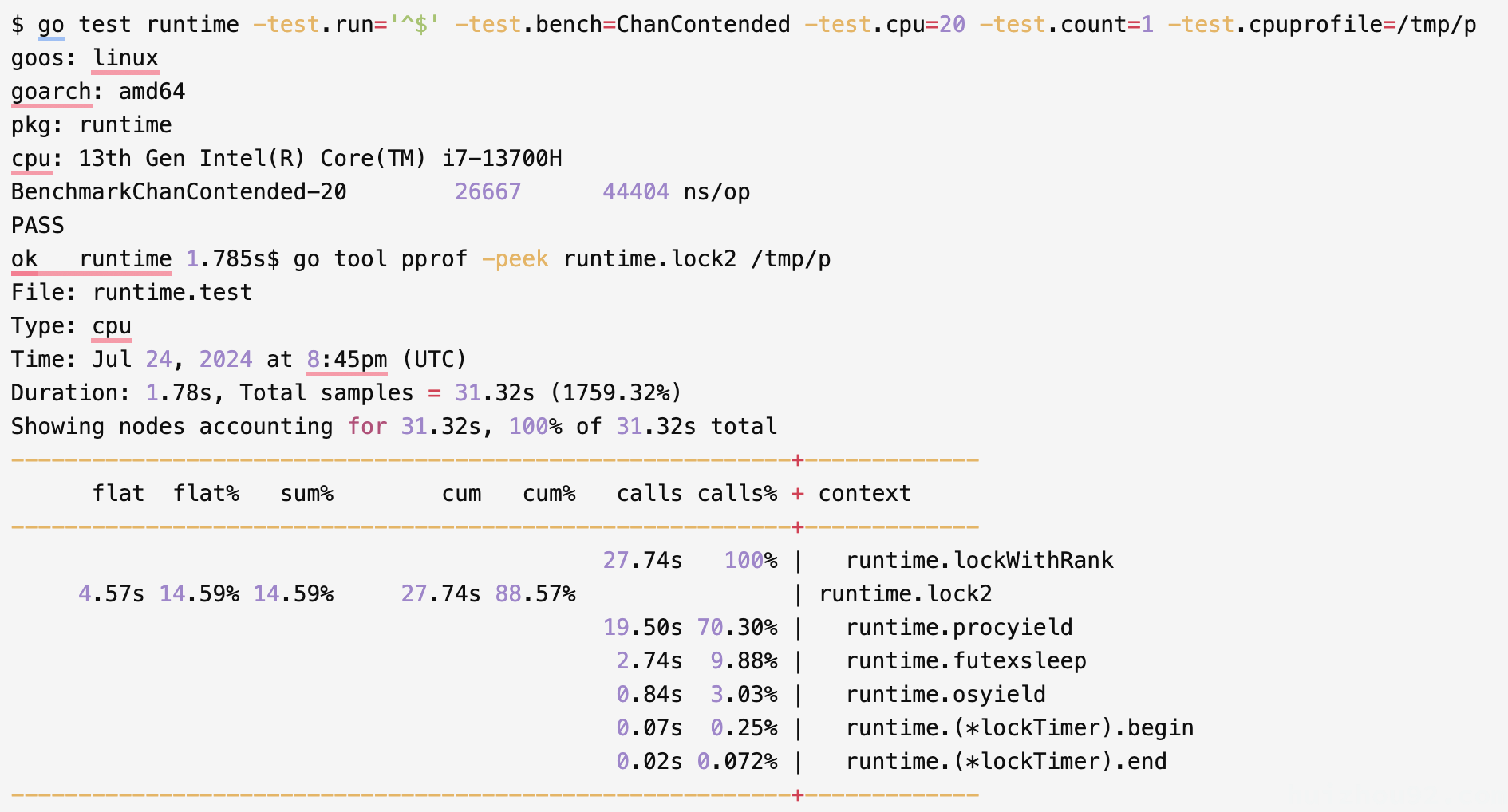
这些 lock2 相关的线程并没有休眠,而是一直在自旋,这将消耗大量的CPU资源。
新提案:增加spinning状态
通过上述的分析,作者发现在当前的lock2实现中,虽然理论上允许线程睡眠,但实际上导致所有线程都在自旋,导致了更慢的锁传递,带来了不少的性能损耗。
于是提出了新的设计方案《Proposal: Improve scalability of runtime.lock2》
核心优化点
mutex 的状态字添加了一个个新的标志位,称为 “spinning”。
1
2
3
4
5
6
7
|
https://github.com/golang/go/blob/608acff8479640b00c85371d91280b64f5ec9594/src/runtime/lock_spinbit.go#L57
const (
mutexLocked = 0x001
mutexSleeping = 0x002
mutexSpinning = 0x100
...
)
|
使用这个 spinning位来表示是否有一个等待的线程处于 “醒着并循环尝试获取锁” 的状态。线程之间会互相排除进入 spinning状态,但它们不会因为尝试获取这个标志位而阻塞。
metux 的介绍可以参考以前的文章
https://pub.huizhou92.com/go-source-code-sync-mutex-3082a25ef092
Mutex 获取锁分析
1. 快速路径尝试获取锁
1
2
3
4
5
6
7
8
9
|
//https://github.com/golang/go/blob/adc9c455873fef97c5759e4811f0d9c8217fe27b/src/runtime/lock_spinbit.go#L160
k8 := key8(&l.key)
v8 := atomic.Xchg8(k8, mutexLocked)
if v8&mutexLocked == 0 {
if v8&mutexSleeping != 0 {
atomic.Or8(k8, mutexSleeping)
}
return
}
|
fast 模式跟以前变化不大。如果成功(锁之前未被持有)则快速返回。这是最理想的情况,无竞争时的快速路径。
2. 自旋等待阶段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
//https://github.com/golang/go/blob/adc9c455873fef97c5759e4811f0d9c8217fe27b/src/runtime/lock_spinbit.go#L208
if !weSpin && v&mutexSpinning == 0 && atomic.Casuintptr(&l.key, v, v|mutexSpinning) {
v |= mutexSpinning
weSpin = true
}
if weSpin || atTail || mutexPreferLowLatency(l) {
if i < spin {
procyield(mutexActiveSpinSize) //主动自旋
// ...
} else if i < spin+mutexPassiveSpinCount {
osyield() //被动自旋
// ...
}
}
|
- 如果快速路径失败,进入自旋等待阶段。
- 通过 mutexSpinning 标志控制同时只允许一个 goroutine 自旋
- 自旋分为procyield与osyield,两者的区别是:procyield会持续占有CPU,响应会更快,适合极短时间的等待,osyield会临时释放CPU,响应较慢,但是不会占用较多CPU,适用于较长时间的等待。
这种两阶段自旋设计能够在不同竞争强度下都保持较好的性能表现。
- 轻度竞争时主要使用主动自旋,保证低延迟
- 重度竞争时快速进入被动自旋,避免CPU资源浪费
休眠等待阶段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
//https://github.com/golang/go/blob/adc9c455873fef97c5759e4811f0d9c8217fe27b/src/runtime/lock_spinbit.go#L231
// Store the current head of the list of sleeping Ms in our gp.m.mWaitList.next field
gp.m.mWaitList.next = mutexWaitListHead(v)
// Pack a (partial) pointer to this M with the current lock state bits
next := (uintptr(unsafe.Pointer(gp.m)) &^ mutexMMask) | v&mutexMMask | mutexSleeping
if weSpin {
next = next &^ mutexSpinning
}
if atomic.Casuintptr(&l.key, v, next) {
weSpin = false
semasleep(-1)
atTail = gp.m.mWaitList.next == 0
i = 0
}
|
如果自旋失败,goroutine 将进入休眠等待,然后将当前 M 加入等待队列(通过 mWaitList 链表),通过信号量(semasleep)使当前 goroutine 进入休眠,等待持有锁的 goroutine 在解锁时唤醒。
当某个线程解锁互斥锁时,如果发现已经有线程处于 “醒着并旋转” 的状态,就不会唤醒其他线程。在 Go 运行时的背景下,这种设计被称为 spinbit。
这个设计的核心目的是:通过让一个线程负责 “旋转尝试获取锁”,避免所有线程都同时竞争资源,从而减少争用和不必要的线程切换。
效果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
goos: linux
goarch: amd64
pkg: runtime
cpu: 13th Gen Intel(R) Core(TM) i7-13700H
│ old │ new │
│ sec/op │ sec/op vs base │
ChanContended 3.147µ ± 0% 3.703µ ± 0% +17.65% (p=0.000 n=10)
ChanContended-2 4.511µ ± 2% 5.280µ ± 7% +17.06% (p=0.000 n=10)
ChanContended-3 5.726µ ± 2% 12.125µ ± 2% +111.75% (p=0.000 n=10)
ChanContended-4 6.574µ ± 1% 13.356µ ± 4% +103.16% (p=0.000 n=10)
ChanContended-5 7.706µ ± 1% 13.717µ ± 3% +78.00% (p=0.000 n=10)
ChanContended-6 8.830µ ± 1% 13.674µ ± 2% +54.85% (p=0.000 n=10)
ChanContended-7 11.07µ ± 0% 13.59µ ± 2% +22.77% (p=0.000 n=10)
ChanContended-8 13.99µ ± 1% 14.06µ ± 1% ~ (p=0.190 n=10)
ChanContended-9 16.93µ ± 2% 14.04µ ± 3% -17.04% (p=0.000 n=10)
ChanContended-10 20.12µ ± 4% 14.12µ ± 1% -29.80% (p=0.000 n=10)
ChanContended-11 23.96µ ± 2% 14.44µ ± 3% -39.74% (p=0.000 n=10)
ChanContended-12 29.65µ ± 6% 14.61µ ± 3% -50.74% (p=0.000 n=10)
ChanContended-13 33.98µ ± 7% 14.69µ ± 3% -56.76% (p=0.000 n=10)
ChanContended-14 37.90µ ± 1% 14.69µ ± 3% -61.23% (p=0.000 n=10)
ChanContended-15 37.94µ ± 4% 14.89µ ± 5% -60.75% (p=0.000 n=10)
ChanContended-16 39.56µ ± 0% 13.89µ ± 1% -64.89% (p=0.000 n=10)
ChanContended-17 39.56µ ± 0% 14.45µ ± 4% -63.47% (p=0.000 n=10)
ChanContended-18 41.24µ ± 2% 13.95µ ± 3% -66.17% (p=0.000 n=10)
ChanContended-19 42.77µ ± 5% 13.80µ ± 2% -67.74% (p=0.000 n=10)
ChanContended-20 44.26µ ± 2% 13.74µ ± 1% -68.96% (p=0.000 n=10)
geomean 17.60µ 12.46µ -29.22%
|
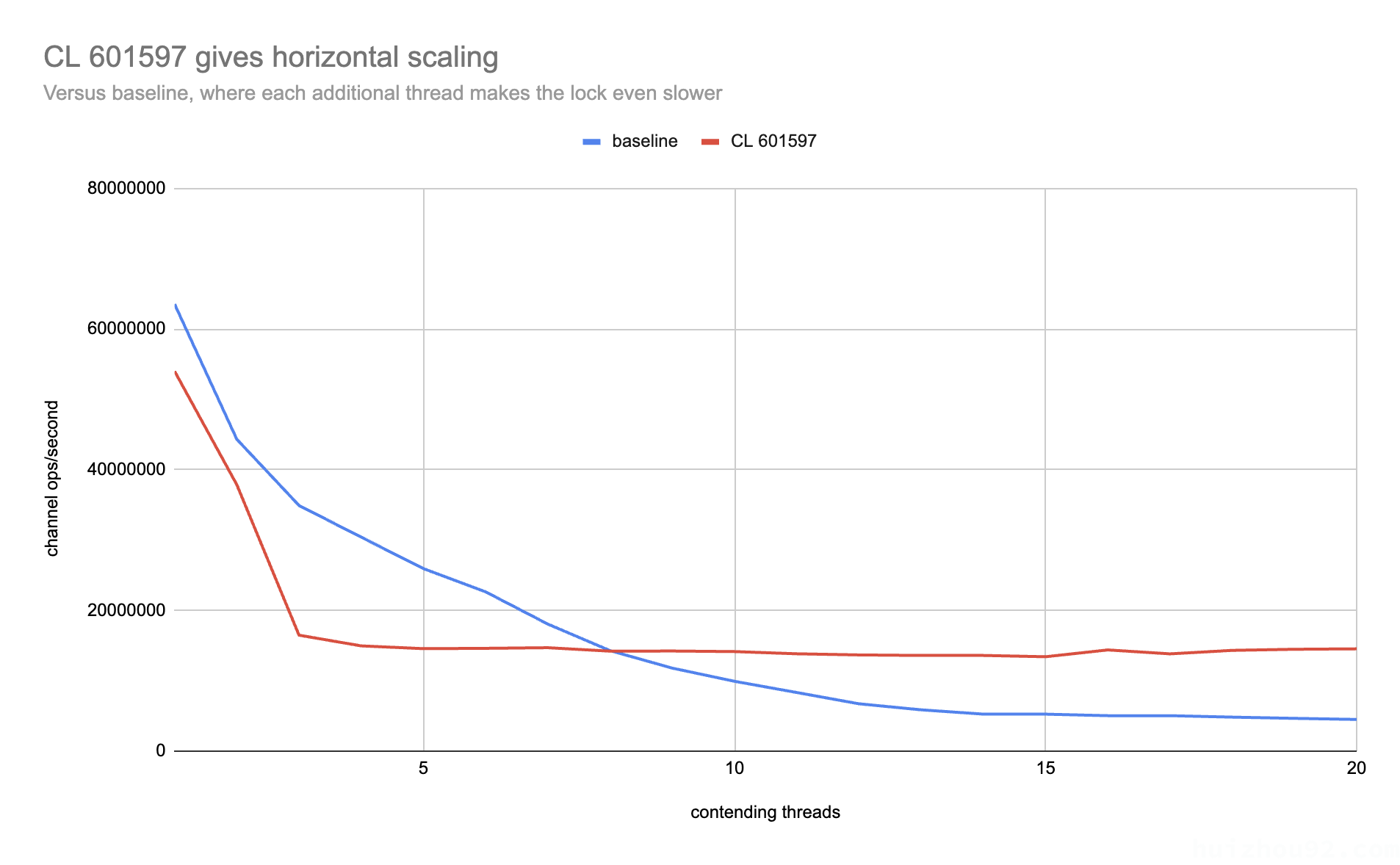
source https://github.com/golang/go/issues/68578#issuecomment-2256792628
虽然在竞争较少的情况下,性能有降低,但是在竞争比较多的地方性能提升显著。平均来说,大约获得 29%的性能提升。期待后续能够优化这种情况吧。
mutex本次修改没涉及API层面改动,所以只要等 Go1.24 正式发布就能自动使用了。该特性通过GOEXPERIMENT=spinbitmutex 来控制,默认是开启的,也可以将它关闭,来使用原来的Mutex。
- 本文长期链接
- 如果您觉得我的博客对你有帮助,请通过 RSS订阅我。
- 或者在X上关注我。
- 如果您有Medium账号,能给我个关注嘛?我的文章第一时间都会发布在Medium。
