原文:Avoiding high GC overhead with large heaps
当分配的内存量相对较小时,Go垃圾收集器 (GC) 工作得非常好,但是如果堆的大小较大,GC过程可能会消耗大量 的CPU。在极端情况下,它甚至可能无法完成任务(GC算法保证GC不会使用超过50%的CPU时间,如果超过这阈值,会导致内存泄露)。
有什么问题?
GC的工作是确定哪些内存块可被释放,它通过扫描内存中分配的指针来完成这一任务。简单来说,如果没有指针指向某个内存分配,则可释放该内存分配。这种方法非常有效,但需要扫描的内存越多,所需时间就越长。
这是一个大问题吗?
有多严重?我们来揭晓!以下是 demonstrate 的小程序。我们分配 1e9 个 8 字节指针,即约 8GB 的内存。我们强制执行 GC,并测量它需要多长时间。我们会重复几次以获得一个稳定的值。还调用 runtime.KeepAlive() 以防止编译器优化。
|
|
在我的 2015 年 MBP上,输出结果如下所示。
|
|
GC需要花费0.5S以上的时间。我为它分配了10e9个指针。事实上,每检查一个指针所花费的时间不到一纳秒。对于检查指针的速度来说,这已经相当快了。
然后呢?
如果我们的应用程序真的需要在内存中维持一个巨大的Map或者数组,那可就麻烦了。如果GC坚持定期扫描我们分配的全部内存,我们就会损失大量的CPU时间。有什么办法可以解决这个问题吗? 我们基本上只有两种选择:要么对 GC 隐藏内存,要么使GC对其不感兴趣,不扫描它。
让GC不扫描这部分内存
怎样才能让GC不扫描这部分内存?GC在寻找指针。如果我们分配的对象的类型不包含指针,GC还会扫描吗?
我们可以尝试一下。在下面的例子中,我们分配与之前完全相同数量的内存,但这次我们的分配中没有指针类型。我们分配了一块包含十亿个 8 字节整数(ints)的切片内存。再次强调,这是大约8GB的内存。
|
|
再次在我的 2015 年款 MBP上运行了这个程序,结果如下:
|
|
GC 的速度快了足足一千倍,而所分配的内存数量却完全一样。原来 Go 语言内存管理器能识别每一次内存分配的类型,并且会给不包含指针的内存打上标记,这样 GC 在扫描内存时就能跳过它们。如果我们能让大内存中不包含指针的话,那就太棒了。
将内存隐藏起来
我们可以做另一件事就是将分配的内存隐藏起来,让GC看不见。如果我们直接向操作系统请求内存,GC就永远不会知道它,也就不会扫描它。与我们之前例子的做法相比,这样做稍微有些复杂!这里是我们的第一个程序的等价版本,我们使用 mmap 系统调用直接从操作系统内核分配 []*int 亿(1e9)个条目。注意,这只在 *unix 系统上有效,但在 Windows 上也有类似的方法。
|
|
这次的GC耗时为:
|
|
如果您想了解 a := *(*[]*int)(unsafe.Pointer(&slice)) ,请浏览 https://blog.gopheracademy.com/advent-2017/unsafe-pointer-and-system-calls/。
现在,这部分内存对GC是不可见的。这会带来一个有趣的后果,即存储在这一内存中的指针,不会阻止它们指向的‘正常’分配的内存被GC回收。而这会带来糟糕的后果,我们很容易就可证明。
在这里,我们尝试将 0、1 和 2 存入堆分配的整数中,并将指向它们的指针存入mmap分配的切片中(不受GC管控)。在为每个整数分配内存并存储指向它们的指针后,我们强制执行一次垃圾回收。
我们的输出在这里。在每次垃圾回收后,支持我们整数的内存都会被释放并可能被重新使用。所以,我们的数据并不像我们预期的那样,很幸运程序没有崩溃。
|
|
这样显然是不行的。如果我们修改成使用通常分配的 []*int ,如下所示,就可以得到预期的结果。
|
|
输出如下:
|
|
问题的本质
所以,最终我们证明指针是我们的敌人,无论我们在堆上分配了大量内存,还是试图通过将数据移动到我们自己的非堆内存分配来规避这个问题。如果我们能在分配的类型中避免使用指针,就不会造成GC的负担,从而无需使用任何奇技淫巧。如果我们使用非堆内存分配,则需要避免存储对堆内存的指针,除非这些内存也被GC可访问内存所引用。
我们如何才能避免使用指针?
在大的堆内存中,指针是邪恶的,必须避免。但是要避免它们,你就必须能识别出来,而它们并不总是很明显。字符串、切片和 time.Time 均包含指针。如果你在内存中存储了大量这些数据,就可能需要采取一些措施。
我遇到大堆问题时,主要原因有以下几点。
- 许多字符串
- 将对象上的时间戳使用 time.Time 进行翻译。
- 值为
slice的map - key 为
string的map
对于处理这些问题的不同策略,有很多话要说。在本帖中,我只讨论一种处理字符串的方法。
将字符串slice变成一个带索引的数组。
一条字符串由两个部分组成。一个是字符串头,它会告诉你字符串的长度以及在哪里找到原始数据;另一个就是实际的字符串数据了,它只是一系列字节的顺序。
当你将一个字符串变量传递给一个函数时,只有字符串的头被写入栈中,如果你保持一个字符串切片,那么切片中的字符串头就会出现。
字符串头的定义是 reflect.StringHeader ,长这样:
|
|
字符串头包含指针,所以我们不想存储字符串!
- 如果你的字符串只取几种固定的值,可以考虑使用整数常量替代
- 将日期和时间作为字符串存储的话,不妨将它们解析为整数并存储起来
- 如果你真的需要很多string,那就请继续阅读……
假设我们正在存储一亿条记录。为了简单起见,我们假定这是个巨大的全局变量var mystrings []string。
这里有什么?mystrings的基础架构是一个reflect.SliceHeader,它与我们刚刚看到的reflect.StringHeader相似。
|
|
对于 mystrings ,Len 和 Cap 都是 10e8,Data 会指向一个足够容纳 10e8 个 StringHeader 的连续内存区域。这一块内存包含指针,因此会被GC扫描。
字符串本身由两部分组成。这个切片中包含的是StringHeaders,以及每个字符串的数据,这些数据是单独的分配,数据本身没有包含指针。从垃圾回收的角度来看,问题在于字符串头部,而不是字符串数据本身。字符串数据不包含指针,因此不会被扫描。庞大的字符串头部数组包含指针,因此必须在每个垃圾回收周期中进行扫描。
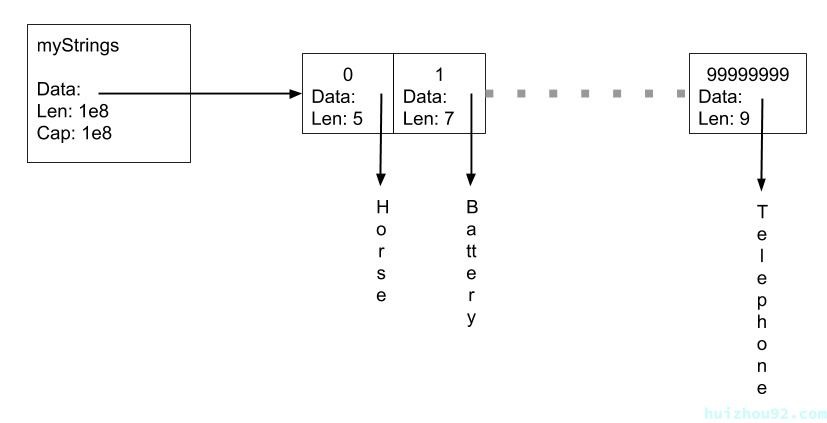
如果所有字符串的字节都存放在一块内存中,我们可以通过每个字符串相对于内存起始和终止位置的偏移量来跟踪它们。通过跟踪偏移量,我们就可以在大型slice中消除指针,跳过垃圾回收的扫描。
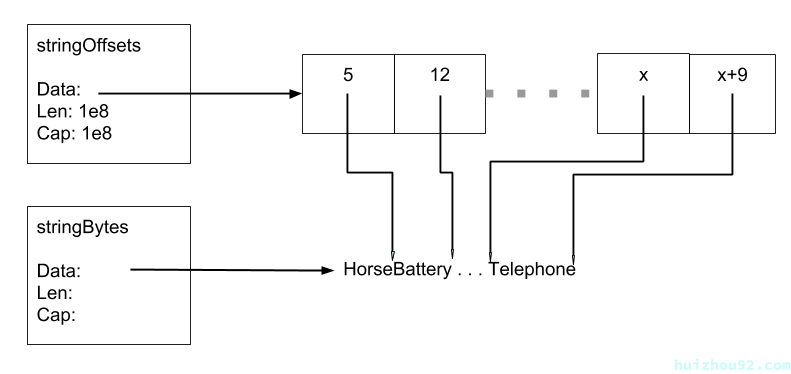
这样做的坏处就是,丧失了slice 操作的便利性,slice 的修改变得特别复杂,我们为将字符串体复制到大的字节切片上增加了开销。
这里有一个小程序来演示这个想法。我们将创建 10e8个字符串,将这些字符串的字节复制到一个大的字节切片中,并存储偏移量。可以看到GC耗时非常少,然后通过显示前 10 个字符串来证明我们可以检索这些字符串。
|
|
|
|
如果你永远不需要修改这些字符串,可以将它转换为一个更大数据块的索引方式,从而避免大量指针。如果你感兴趣,我实现了一个更复杂一点的东西,它遵循这一原则。
我之前多次在博客中提到过遇到由大堆引发的垃圾回收(GC)问题。事实上,每当我遇到这个问题时,我都感到惊讶,并再次在博客中写道它。希望看到这里时,如果在你项目中发现这个问题的话,不会让你感到惊讶,你甚至会提前想到这个问题。
以下是一些资源,希望对你解决这些问题有所帮助。
- 我上面提到的string store
- interning library 一个用于 Go 语言的字符串 interning 库,
- variation 将字符串 ID 转换为整数 ID,从而可以用于快速比较和数组/切片查找。