从Go 编译器的角度来看,内存会被分配到两个地方: stack 和 heap。对于业务开发人员来说,这两种方式,没什么区别,通常开发者并不需要关心内存分配在栈上,还是堆上,因为这都是编译器自动完成的。但是从性能的角度出发,在栈上分配内存和在堆上分配内存,性能差异是非常大的。在函数中申请一个对象,如果分配在栈中,函数执行结束时自动回收。如果分配在堆中,则是由GC算法在某个时间点进行垃圾回收,其中的原理比较复杂。总之,分配堆内存比栈内存需要更多的开销,这种将内存分配到堆的现象就是内存逃逸。我们在写代码的时候,应当尽量避免堆内存分配。
为什么会有内存逃逸?
原因其实很简单,编译器无法确定变量的生存周期,或者栈空间放不下那么大的内存。Go 编译器怎么知道某个变量需要分配在栈上,还是堆上呢?编译器决定内存分配位置的方式,就称之为逃逸分析(escape analysis)。逃逸分析由编译器完成,作用于编译阶段。可以用 -gcflags=-m 来观察变量是否逃逸。
内存逃逸对性能的影响
可以做一个很简单的benchmark测试, BenchmarkInt 是一个指针数组,&j 会产生内存逃逸, BenchmarkInt2 则不会产生 内存逃逸。
|
|
运行结果是:
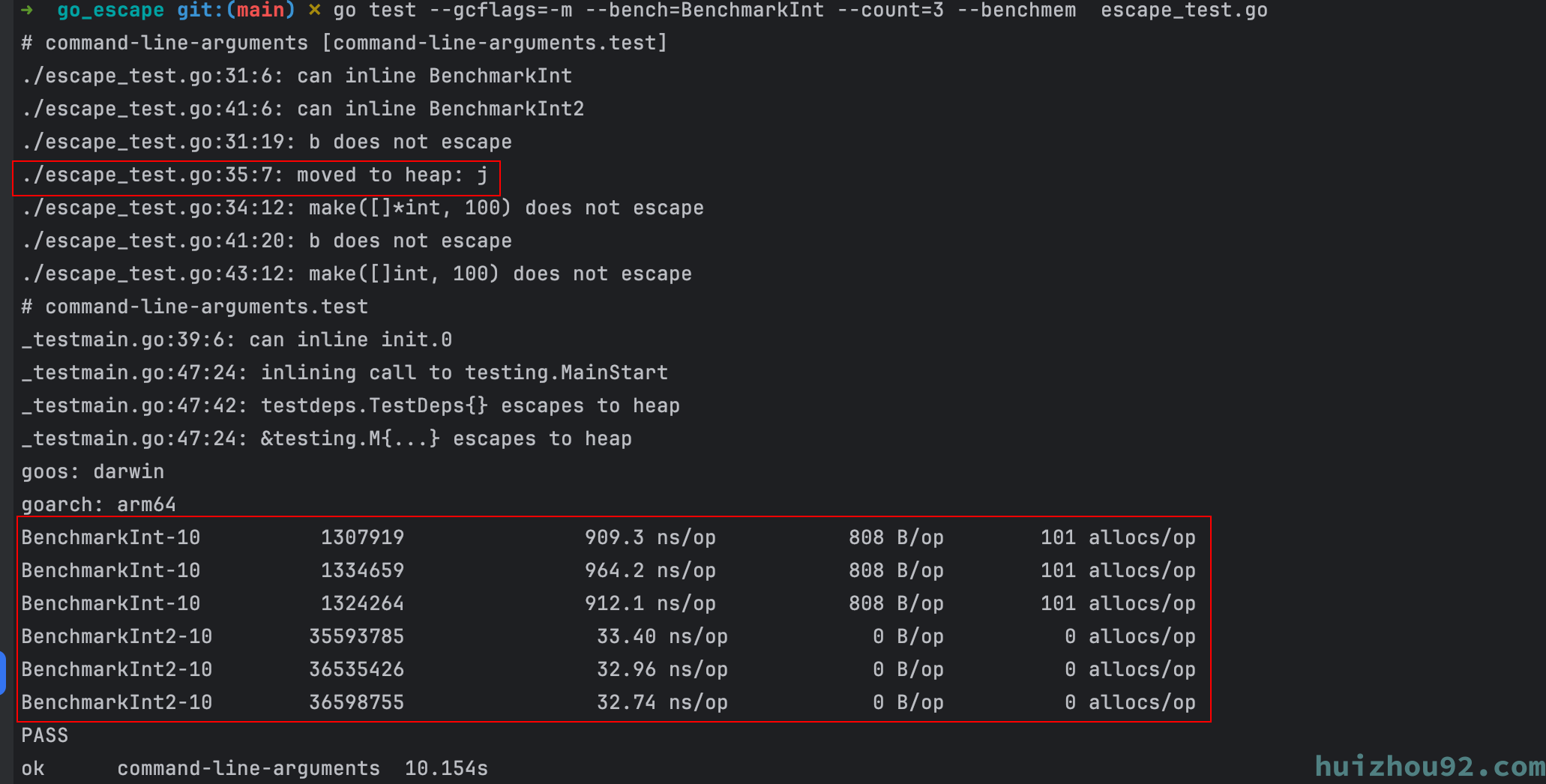
BenchmarkInt2 的比BenchmarkInt 快30倍,并且没有一次内存分配,BenchmarkInt 则有101次内存分配。 从这个测试我们就知道为什么有必要进行内存逃逸分析了。
内存逃逸的典型场景
变量逃逸 & 指针逃逸
当一个变量的生命周期超出函数范围时,编译器会将其分配到堆上,我们叫这种现象为内存变量逃逸,或者指针逃逸。
|
|
栈溢出
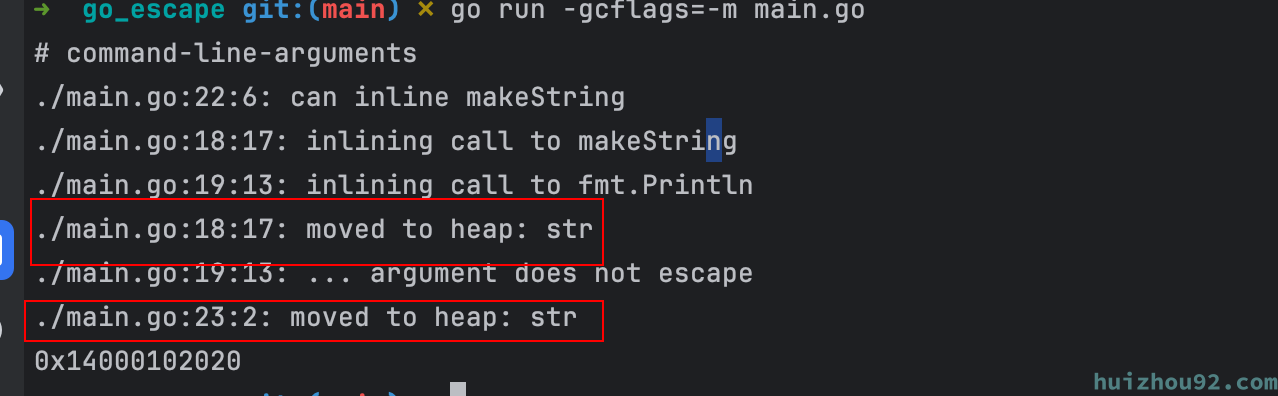
操作系统对内核线程使用的栈空间是有大小限制的,在64位操作系统上面,这个大小通常是8 MB。可以使用 ulimit -a 命令查看计算机允许的最大的栈内存大小。Go runtime 在 goroutine 需要的时候动态地分配栈空间,goroutine 的初始栈大小为 2 KB。当 goroutine 被调度时,会绑定内核线程执行,栈空间大小也不会超过操作系统的限制。对于go 的编译器来说,超过一定大小的局部变量将逃逸到堆上,一般是64KB。比如这段代码尝试创建一个占用 8193 字节的数组: 8192 * 8 / 1024 = 64k
|
|
当数组大于 8192 的时候就逃逸到了堆上。
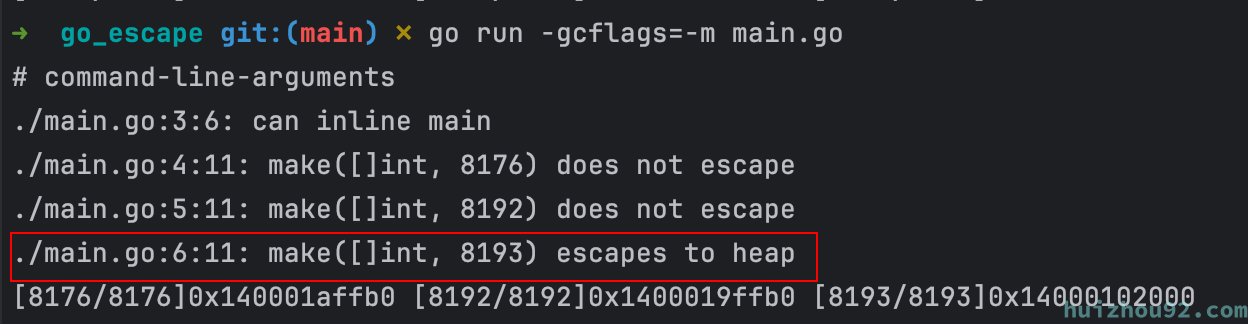
不确定大小的变量
|
|
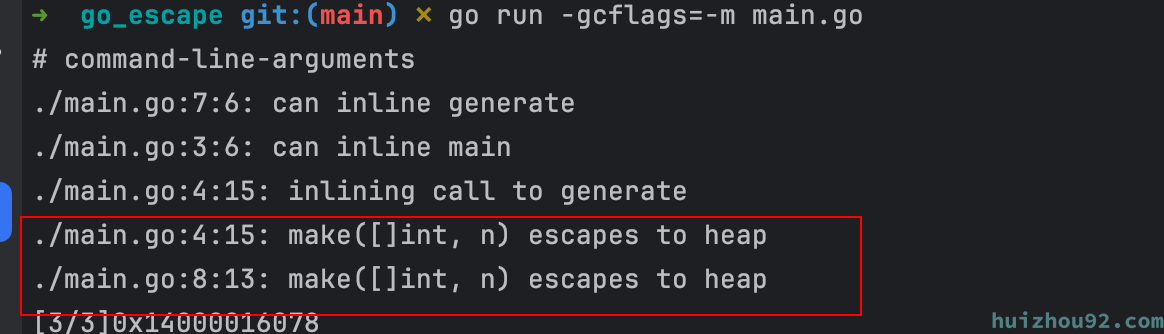
generate 的参数是在运行时传入的,所以编译器不能确定他的大小, 逃逸到堆上,
interface{} 动态类型逃逸
在Go语言中,空接口即 interface{} 可以表示任意的类型,如果函数参数为 interface{},编译期间很难确定其参数的具体类型,也会发生逃逸。
比如:
|
|
运行结果是:
因为 fmt.Println 的参数是一个any(也就是interface{}) 所以v会发生逃逸
闭包 Closure
比如下面的例子
|
|
Increase() 返回值是一个闭包函数,该闭包函数访问了外部变量 n,那变量 n 将会一直存在,直到 in 被销毁。很显然,变量 n 占用的内存不能随着函数 Increase() 的退出而回收,因此将会逃逸到堆上。
手动强制避免逃逸
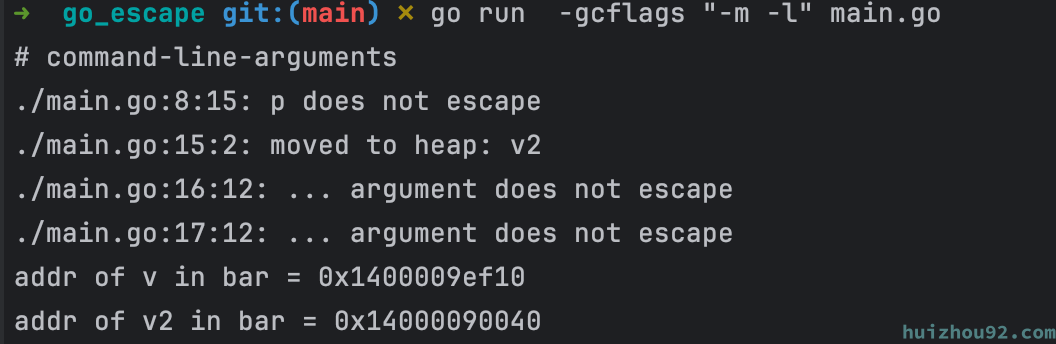
在 interface{} 动态类型逃逸 的例子中, 我们就是打印了一个"Hello,World",但是还是产生了内存逃逸,我们可以确定的一点是:v 不需要逃逸,但若使用fmt.Printf,我们无法阻拦a的逃逸。那是否有一种方法可以干扰逃逸分析,使逃逸分析认为需要在堆上分配的内存对象而我们确定认为不需要逃逸的对象避免逃逸呢?在Go runtime代码中,我们发现了一个函数:
|
|
在Go标准库和rruntime实现中,该函数得到大量使用。该函数的实现逻辑使得我们传入的指针值与其返回的指针值是一样的。该函数只是通过uintptr做了一次转换,而这次转换将指针转换成了数值,这“切断”了逃逸分析的数据流跟踪,导致传入的指针避免逃逸。

我们改一下上面的例子
|
|
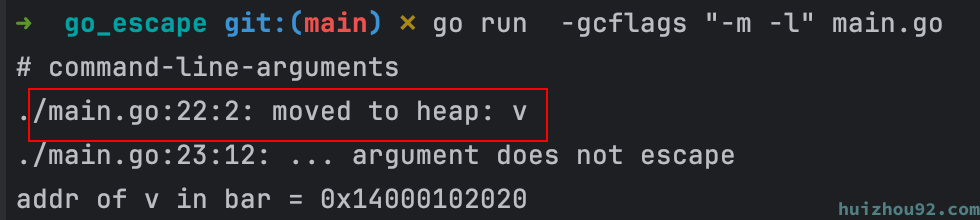
运行结果如图所示,v 没有发生内存逃逸,v2有内存逃逸。
总结
在一般的开发过程中,我们一般很少会涉及内存逃逸分析,根据经验来看,优化一个锁得到的性能提升,比你做十次内存逃逸分析结果还要好。在平时的开发过程中,我们只需要明白一件事就好:
- 传值会拷贝整个对象,而传指针只会拷贝指针地址,指向的对象是同一个。传指针可以减少值的拷贝,但是会导致内存分配逃逸到堆中,增加垃圾回收(GC)的负担。在对象频繁创建和删除的场景下,传递指针导致的 GC 开销可能会严重影响性能。
一般情况下,对于需要修改原对象值,或占用内存比较大的结构体,选择传指针。对于只读的占用内存较小的结构体,直接传值能够获得更好的性能。
参考资料
- https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast
- http://www.wingtecher.com/themes/WingTecherResearch/assets/papers/ICSE20.pdf
- https://tonybai.com/2021/05/24/understand-go-escape-analysis-by-example/
- https://docs.google.com/document/d/1CxgUBPlx9iJzkz9JWkb6tIpTe5q32QDmz8l0BouG0Cw/preview#
- https://dave.cheney.net/2018/01/08/gos-hidden-pragmas
- http://www.wingtecher.com/themes/WingTecherResearch/assets/papers/ICSE20.pdf