
场景描述
假设有这么一个场景: 假设100w个Uber司机,司机客户端每隔10分钟上报一次数据,如果十分钟没有上报数据,服务端会将这个司机设置为离线状态,不给他派单。
我们应该如何实现这个功能?
通常的情况下,我们会使用redis的zset等第三方组件来实现这个功能,但是如果不使用第三方组件呢?只使用内存呢?大概有这么几种方案:
使用 Timer
- 用一个Map<uid, last_time>来记录每一个uid最近一次上报时间;
- 当某个用户uid存活上报时,实时更新这个Map;
- 启动一个timer,轮询扫描这个Map,看每个uid的last_time是否超过30s,如果超过则进行超时处理;
|
|
缺点:这种方式效率不高,因为需要定期轮询整个Map,时间复杂度较高。
使用gorutine 管理
另一种方案是为每个司机分配一个Goroutine来管理其心跳超时。
|
|
缺点:虽然不需要轮询,但每个Goroutine都有栈空间,当司机数量非常多时,内存消耗会很大。此外,Timer的创建和删除时间复杂度为O(log n),效率有待提升。
前面铺垫了这么久,终于轮到我们的主角了,时间轮。
时间轮算法
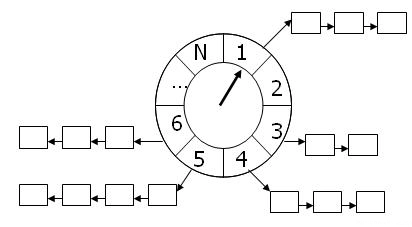
时间轮是一个比较有趣的算法,他最早刊登在George Varghese和Tony Lauck的论文里。 时间轮算法的核心逻辑是:
- 使用一个固定大小的数组表示时间轮,每个槽(slot)对应一个时间间隔。
- 每个slot中保存一个slice,用于存储当前时间段到期的任务,同时有一个Map<uid,slot> 记录uid对应的solt。
- 使用一个定时器定期(interval)推动时间轮向前走一格(position),处理当前solt(position)的所有任务.
所以我们可以使用时间轮算法来实现功能。我们可以将interval设置成1s, 时间轮的slots为600,司机上报数据的时候,将记录插入到position-1的slot里面。
一个简单的Demo:
https://gist.github.com/hxzhouh/5e2cedc633bae0a7cf27d9f5d47bef01
优势
- 时间轮算法添加任务只需要将任务append 到对应的slot里面,所以时间复杂度是O(1)
- 时间轮槽位固定,内存占用可控。
- 适合处理大量定时任务
劣势
- 时间轮的精度受限于interval 的大小。
- 如果任务分配不均匀的话,Delete Task 可能退化到 O(n)
所以时间轮特别适合以下场景的任务:
- 大量任务的快速插入
- 对时间精度要求不是特别高的场景
- 任务分布相对均匀的情况
时间轮的优化
简单时间轮
将所有任务的换算为多少秒或毫秒(Interval)后到期,维护一个最大过期值(Interval)长度的数组。比如有10个任务,分别是1s,3s,100s 后到期,就建一个100长度的数组,数组的index就是每个任务的过期值(Interval),当前时间作为第一个元素,那么第二个元素就是1s 后到期的任务,第三个是2s 后到期的任务,依次类推。当前时间随着时钟的前进(tick),逐步发现过期的任务。
- 开始调度一个任务(start_timer): 来一个新的调度任务时,换算任务的到期时间为到期值(Interval),直接放入相应的数组元素内即可,时间复杂度是O(1)。
- 时钟走一格,需要做的操作(per_tick_bookkeeping):时钟走一格直接拿出这一格内的任务执行即可,时间复杂度是O(1)。
Hash有序时间轮 (Demo中使用的就是这种方式的变种)
简单时间轮虽然很完美,所有的操作时间复杂度都是O(1),但是当任务最大到期时间值非常大时,比如100w,构建这样一个数组是非常耗费内存的。可以改进一下,仍然使用时间轮,但是是用hash的方式将所有任务放到一定大小的数组内。 这个数组长度可以想象为时间轮的格子数量,轮盘大小(W)。
hash的数值仍然是每个任务的到期值(Interval),最简单的是轮盘大小(W)取值为2的幂次方,Interval哈希W后取余,余数作为轮盘数组的index,数组每个元素可能会有多个任务,把这些任务按照过期的绝对时间排序,这样就形成了一个链表,或者叫做时间轮上的一个桶。
但是Hash有序时间轮 还是有一个问题:
因为只使用了一个时间轮,处理每一格的定时任务列表的时间复杂度是 O(n),如果定时任务数量很大,分摊到每一格的定时任务列表就会很长,这样的处理性能显然是让人无法接受的。
层级时间轮
层级时间轮通过使用多个时间轮,并且对每个时间轮采用不同的 u,可以有效地解决简单时间轮及其变体实现的问题。
参考 Kafka 的 Purgatory 中的层级时间轮实现:
- 每一层时间轮的大小都固定为 n,第一层时间轮的时间单位为u,那么第二层时间轮(我们称之为第一层时间轮的溢出时间轮 Overflow Wheel)的时间单位就为 n*u,以此类推。
- 除了第一层时间轮是固定创建的,其他层的时间轮(均为溢出时间轮)都是按需创建的。
- 原先插入到高层时间轮(溢出时间轮)的定时任务,随着时间的流逝,会被降级重新插入到低层时间轮中。
总结
总结一下几种算法的性能。
| 算法 | 添加任务复杂度 | 删除任务复杂度 | 内存开销 | 适用场景 |
|---|---|---|---|---|
| Single Timer | O(1)O(1) | O(1)O(1) | 低 | 适用于任务数量少、精度要求高的场景。 |
| Multi Timer | O(logn)O(\log n) | O(logn)O(\log n) | 中 | 适用于任务数量中等、任务间相互独立的场景,但内存开销较高。 |
| Simple Timing Wheel | O(1)O(1) | O(n)O(n) | 高(大数组) | 任务分布均匀、到期时间精度要求较低的场景。 |
| Hash Timing Wheel | O(1)O(1) | O(n)O(n) | 中 | 任务数量较多、分布不均匀但对精度容忍较高的场景。 |
| Hierarchical Timing Wheel | O(1)O(1) | O(logn)O(\log n) | 低到中 | 适用于大规模任务、层级管理复杂任务、需要较长生命周期的任务调度场景(如 Kafka 和 Netty)。 |
参考资料
- 真实世界中的时间轮
- Netty4 的 HashedWheelTimer。
- Kafka 的 Purgatory。
- go-zero 的NewTimingWheel
- Hashed and Hierarchical Timing Wheels