As an ordinary person, when you browse the web, you may not realize that the web pages sent to you by the server are actually compressed.
If you like a programmer, press F12 in the browser, you’ll find something like this:
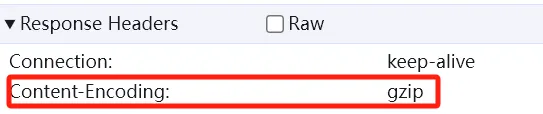
It means: In order to save bandwidth and provide speed, I (the server) compressed the content using gzip, and you (the browser) need to decompress it to view it!
In HTTP compression, besides gzip, there are also algorithms like compress, deflate, br, etc., which can be dazzling.
However, all these compression algorithms have an ancestor: LZ algorithm.
LZ comes from the names of two people: Abraham Lempel and Jacob Ziv.

Both of them passed away in 2023, living a long life, with Lempel living to be 86 years old and Ziv living to be 91 years old.
Origin
Data compression can be divided into two types: lossy compression, such as MP3, JPEG, where some unimportant data is deleted during compression, and lossless compression, where binary bits magically disappear, making files significantly smaller, facilitating storage and transmission.
In 1948, after Claude Shannon founded information theory, everyone has been working on one thing: how to find the optimal coding to compress a piece of information.
Shannon and Fano were the first to propose the Shannon-Fano coding.

It constructs a binary tree from top to bottom by grouping symbols.
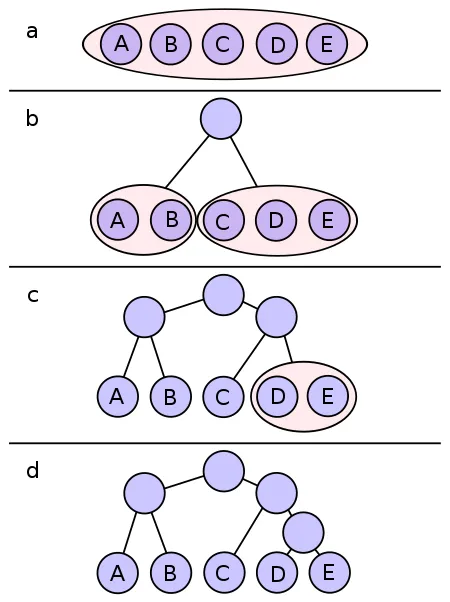
However, this method is not the optimal solution and the encoding is not a prefix code, making it prone to ambiguity.
Later, while teaching information theory at MIT, Fano challenged his students: either take the final exam or improve existing data compression algorithms.
A graduate student named Huffman didn’t like exams, so he chose the latter path.
Huffman didn’t know that even the famous Shannon struggled with this problem. He researched for several months, developed various methods, but none worked.
Just as he was about to give up and throw his notes into the trash, a wonderful and elegant algorithm crossed his mind: build a binary tree from bottom to top based on the frequency of characters, which is the famous Huffman algorithm.
Huffman’s algorithm is called “optimal coding” and achieves two goals:
(1) No character encoding is a prefix of another character encoding.
(2) The total length of the information encoding is minimized.
Although the Huffman algorithm is excellent, it has a huge limitation: it requires obtaining the probability of each character appearing first, and then compression encoding can be done, which is often impossible in many cases.
In the 1970s, with the emergence of the Internet, this problem became more prominent.
Is it possible to compress data while reading it?
Breakthrough
Ziv and Lempel from the Technion-Israel Institute of Technology jointly challenged this problem.
The two were a good team, with Ziv being good at statistics and information theory, while Lempel excelled in Boolean algebra and computer science.

In 1977, they both came to Bell Labs for academic sabbaticals.
Academic sabbatical, also known as “intellectual leave,” gives you a long period of
leave (like six months) after working for a few years, during which you can do whatever you want, and it’s paid.
The sabbaticals of the big shots are interesting. For example, Ken Thompson, the inventor of Unix, returned to his alma mater, Berkeley, during his sabbatical and spread Unix there, inspiring Bill Joy and others to develop BSD.
Ziv and Lempel were similar. They went to Bell Labs in the United States for academic sabbaticals and co-authored a paper during their “sabbatical”: “A Universal Algorithm for Sequential Data Compression,” proposing an algorithm based on a “sliding window,” which does not directly consider character frequencies but instead finds repeated data blocks (such as strings, byte sequences, etc.) and references the positions where these data blocks appeared previously.

This algorithm is LZ77, which is applicable to any type of data, requires no preprocessing (statistical character appearance probabilities), and achieves extremely high compression ratios with just one pass.
The following year, they continued their efforts and improved LZ77 to become LZ78, which could perfectly reconstruct data from compressed data and was more efficient than previous algorithms.
Chaos
An invaluable treasure like the LZ algorithm remained in the theoretical realm for several years without widespread use.
It wasn’t until 1984, when Terry Welch of DEC created the LZW algorithm based on LZ, which was used in Unix’s compress program.
With the widespread dissemination of Unix, the LZ algorithm began to enter the fast lane of rapid development.
However, it also entered an era of chaotic competition.
In 1985, Thom Henderson, while downloading files from BBS, found it tedious to download one by one, as dial-up internet was too slow. So he wrote a software called ARC, which could compress multiple files into one, making it much more convenient.
In 1986, Phillip Katz discovered ARC, liked it, but felt that the compression speed was too slow. So he rolled up his sleeves, rewrote the key compression and decompression parts in assembly language, and created PKARC, which he started selling.


When Thom Henderson saw his business being snatched away, he sued Phillip Katz, and the reasons were sufficient: the comments and spelling errors in your PKARC are the same as my ARC, you’re plagiarizing! Also, while my ARC is open source, the protocol specifies that you can only view it, not modify it!
In the end, ARC won the lawsuit, and Phillip Katz paid tens of thousands of dollars in damages.
Genius Phillip Katz was naturally not satisfied. He studied the LZ77 algorithm and the Huffman algorithm, combined them, and created a new compression algorithm (deflate) and a new file format (zip), as well as the new software PKZIP.

PKZIP quickly outperformed ARC in both compression ratio and decompression speed, and quickly dominated the DOS era.
Since the ZIP format was open, the open-source info-zip group also released the open-source, free unzip and zip, implementing the deflate algorithm.
Later, Jean-loup Gailly and Mark Adler developed the famous gzip (file format + utility) based on deflate, replacing compress on Unix.

gzip is the HTTP compression format seen at the beginning of the article.
In 1991, Nico Mak felt dissatisfied with the command line of PKZIP, so he developed a front-end for Windows 3.1 based on PKZIP (later replaced by the open-source info-zip), allowing people to compress files using a graphical interface. This is the famous WinZip.
Despite WinZip’s success, it was still “parasitic” on the Windows platform.
Users find that WinZip has an exquisite interface and is user-friendly. There is no need to remember those annoying parameters and compression can be completed with a few clicks of the mouse.
WinZip quickly took over all PCs and became one of the most popular shareware programs in the 1990s.
Windows intervened and simply integrated Zip functionality into the operating system, ending everything.
Conclusion
From LZ77 to LZW, compress, Deflate, gzip… Lossless compression algorithms have been continuously patched and gradually formed into a huge family. However, no matter how they change, their principles and ideas are not much different from the original LZ algorithm.
These algorithms help us compress images, compress text, compress content transmitted over the Internet, and have become an indispensable part of our daily lives.
It’s no exaggeration to say that the LZ algorithm and its descendants have dominated the world.
- Long Time Link
- If you find my blog helpful, please subscribe to me via RSS
- Or follow me on X
- If you have a Medium account, follow me there. My articles will be published there as soon as possible.