Kafka is known for addressing large-scale data processing problems and is widely deployed in the infrastructure of many well-known companies. As early as 2015, LinkedIn had 60 clusters with 1100 Brokers, processing 13 million messages per second.
But it turns out that scale isn’t the only thing Kafka excels at. Its advocated programming paradigm – partitioned, ordered, event processing – is a good solution for many problems you may encounter. For example, if events represent rows to be indexed into a search database, the last modification is the last index, which is essential, otherwise, searches will indefinitely return stale data. Similarly, if events represent user behavior, processing the second event (“user account upgrade”) may depend on the first (“user account creation”). This paradigm differs from traditional job queue systems, where many workers simultaneously pop up events from the queue, which is simple and scalable but breaks any ordering guarantee. Suppose you want ordered processing, but perhaps you don’t want to use Kafka because of its reputation as a difficult-to-operate or expensive heavyweight system. How does Redis, with its “stream” data structure released with version 5.0, compare? Does it solve the same problems?
This article is first published in the medium MPP plan. If you are a medium user, please follow me in medium. Thank you very much.
Kafka Architecture
Let’s first take a look at the basic architecture of Kafka. The fundamental data structure is the topic. It’s a time-ordered record sequence, appended-only. The benefits of using this data structure are well described in Jay Kreps’ classic blog post, The Log.
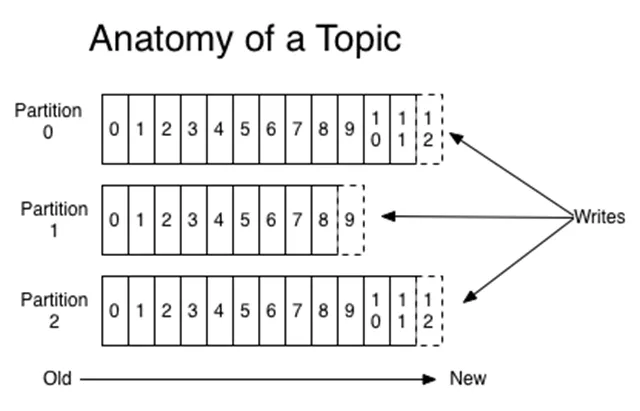
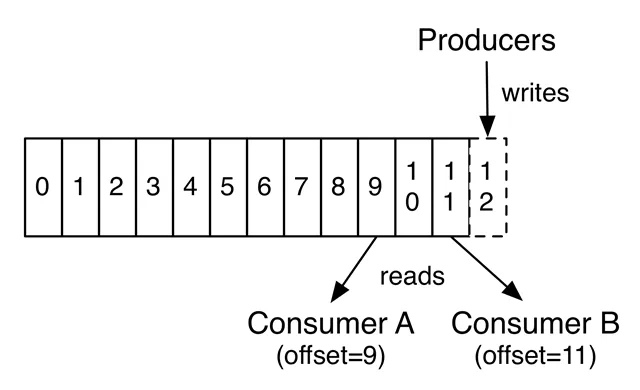
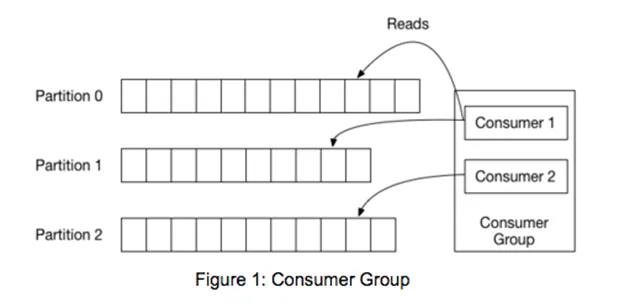
Topics are partitioned to allow them to scale: each topic can be hosted on separate Kafka instances. Records in each partition are assigned consecutive IDs called offsets, which uniquely identify each record in the partition. Consumers process records sequentially, keeping track of the last offset they’ve seen. Since records persist in a topic, multiple consumers can independently process records.
In practice, you may distribute your processing across many machines. To achieve this, Kafka provides an abstraction called a “consumer group,” a group of cooperating processes consuming data from a topic. Partitions of a topic are assigned to members of the group. Then, when members join or leave the group, partitions must be reassigned to ensure each member gets a fair share of the partitions. This is called the rebalancing algorithm.
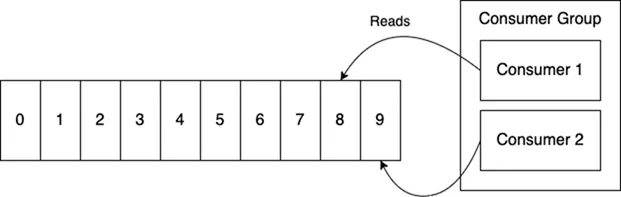
Note that a partition is processed by only one member of the consumer group. (A member may be responsible for multiple partitions.) This ensures strictly ordered processing.
This toolkit is handy. You can quickly scale your processing by adding more workers, while Kafka handles distributed coordination problems.
Redis Stream Data Structure
How does Redis’ “stream” data structure compare? Redis streams conceptually equate to partitioning the abovementioned Kafka topic but with minor differences.
It’s a persistent, ordered event storage (similar to Kafka). It has a configurable maximum length (as opposed to a retention period in Kafka). Events store keys and values akin to Redis Hash (as opposed to a single key value in Kafka). The most significant difference is that consumer groups in Redis are entirely different from those in Kafka.
In Redis, a consumer group is a set of processes that read from the same stream. Redis ensures that events are only delivered to one consumer within the group. For example, in the diagram below, Consumer 1 won’t process ‘9’. It will skip it because Consumer 2 has already seen it. Consumer 1 will get the next event not seen by any other group member.
The role of groups in Redis is to parallelize the processing of a single stream. This structure resembles a traditional job queue. Unfortunately, it loses the ordering guarantee essential to stream processing.
Stream Processing as a Client Library
So, if Redis effectively only provides topics with job queue semantics, how can we build a stream processing engine on top of Redis? If you want Kafka’s features, you need to make them yourself. That means implementing.
- Event partitioning. You need to create N streams and treat each stream as a partition. Then, upon sending, you must decide which partition should receive it based on the event’s hash value or one of its fields.
- A worker partition assignment system. To scale and support multiple workers, you must create an algorithm to distribute partitions among them, ensuring each worker has an exclusive subset, akin to Kafka’s “rebalancing” system.
- Ordered processing with acknowledgment. Each worker needs to iterate through each partition, tracking its offset. Though Redis consumer groups have job queue semantics, they can help here. The trick is to have each group use one consumer and then create a group for each partition. Then, each partition will be processed sequentially, and you can leverage built-in consumer group state tracking. Redis can track not only offsets but also acknowledgments for each event, which is powerful.
This is the absolute minimum requirement. Suppose you want your solution to be robust. In that case, you might also consider error handling: In addition to crashing your workers, perhaps you’d like a mechanism to forward errors to a “dead letter” stream and continue processing.
The good news is that if you’re a Python enthusiast, a newly released library called Runnel addresses these problems and more. You can check out Kafka-like semantics on Redis. Below is what it looks like in one of the Kafka diagrams above.
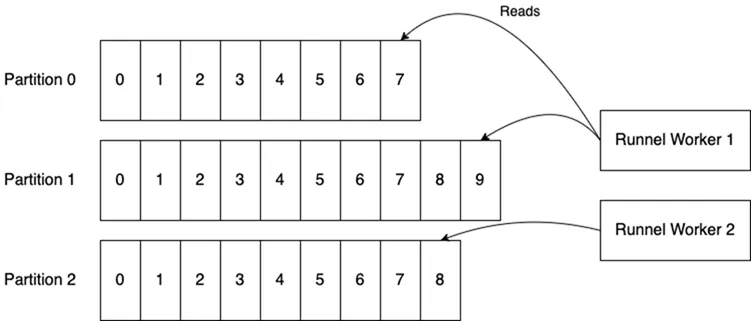
Workers coordinate their ownership of partitions via locks implemented in Redis. They communicate with each other through a special “control” stream. For more information, including a detailed breakdown of the architecture and rebalancing algorithm, please refer to the Runnel documentation.
Summary
Is Redis a good choice for large-scale event processing? There’s a fundamental trade-off: because everything is in memory, you get unparalleled processing speed, but it’s unsuitable for storing unlimited data. With Kafka, you can retain all your events indefinitely. Still, with Redis, you’re storing a fixed window of the most recent events – just enough for your processors to have a comfortable buffer in case they slow down or crash. This means you should also use an external long-term event store, such as S3, to be able to replay them, which adds complexity to your architecture but reduces costs.
The primary motivation for researching this issue is the ease of use and low cost of deploying and operating Redis. That’s why it’s attractive compared to Kafka. It’s also a magical toolkit that stood the test of time, quite impressive. It turns out that, with effort, it can also support the distributed stream processing paradigm.