
What’s Consistent Hashing
First, let me quote a definition from Wikipedia:
In computer science, consistent hashing is a special kind of hashing technique such that when a hash table is resized, only
𝑛/𝑚keys need to be remapped on average where 𝑛 is the number of keys and 𝑚 is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.Consistent hashing evenly distributes cache keys across shards, even if some of the shards crash or become unavailable.
In distributed systems, consistency hash is everywhere. CDN, KV, load balancing, and other places have their shadows. Consistency hash is one of the cornerstone algorithms of distributed systems. It has the following advantages.
- Balanced load: Consistency hash algorithm can evenly distribute data on nodes.
- Scalability: In the consistency hash algorithm, only part of the data needs to be re-mapped when the number of nodes increases or decreases. It is easier for the system to expand horizontally, and the number of nodes can be increased to meet greater load requirements;
- Reduce data migration: Compared with the traditional hash algorithm, the consistent hash algorithm has less data that needs to be re-mapped when nodes increase or decrease, which can greatly reduce the cost of data migration and reduce the instability and delay of the system;
This article aims to learn the consistency hash algorithm and its simple implementation.
This article is first published in the medium MPP plan. If you are a medium user, please follow me in medium. Thank you very much.
Principle of Consistent Hashing Algorithm
Basic Consistent Hashing Algorithm
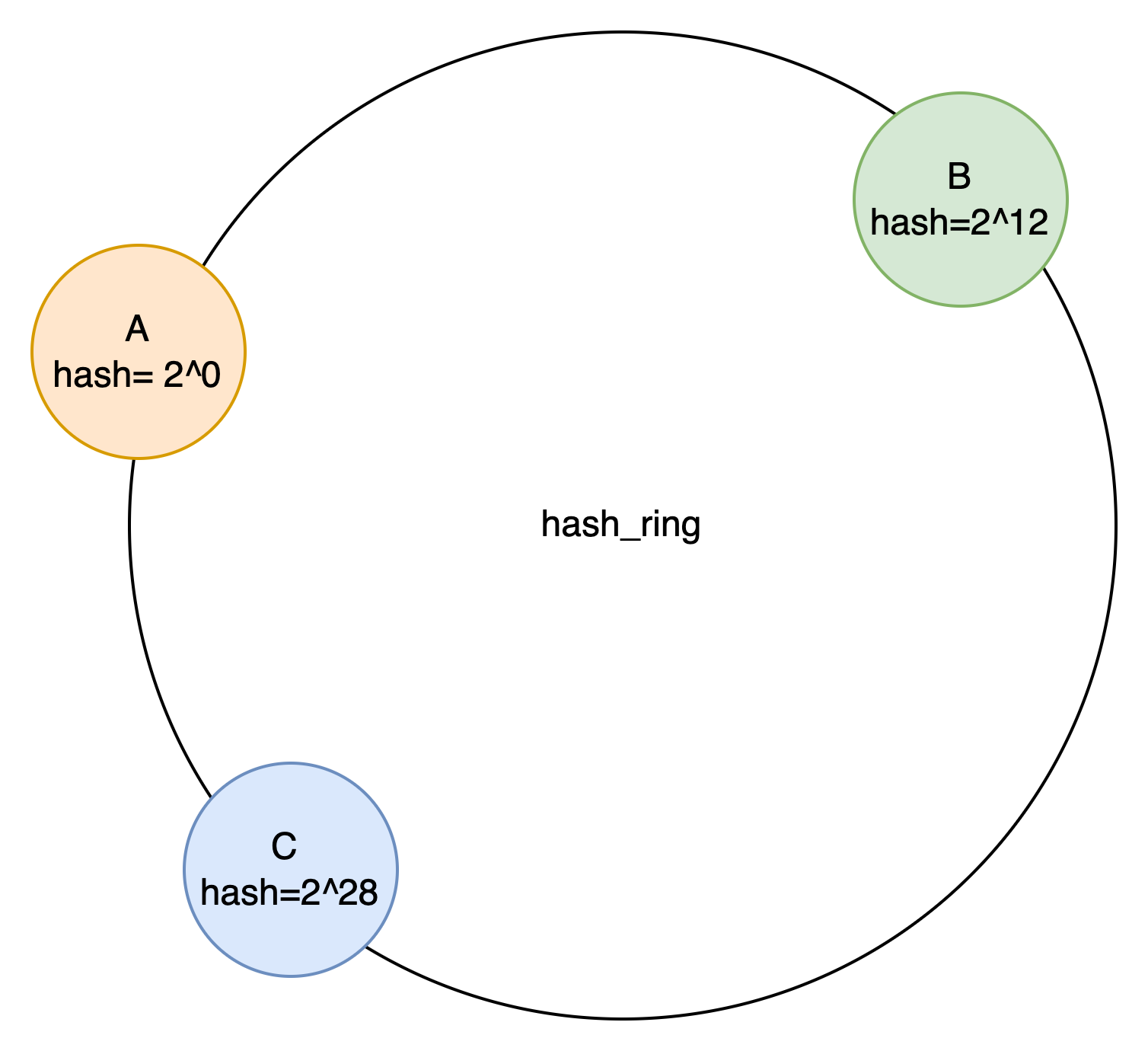
The most basic consistent hashing algorithm is to distribute nodes directly on a ring, thus dividing the value range. After the key goes through hash(x), it falls into different value ranges and is processed by the corresponding node. The most common size of the value range space is: 2^32 - 1. Nodes fall into this space to divide the value ranges belonging to different nodes. As shown in the figure.
Node
The hash range stored by Node A is [0,2^12).
The hash range stored by Node B is [2^12,2^28).
The hash range stored by Node C is [2^28,0).
The basic consistent hashing algorithm mentioned above has obvious drawbacks:
- The random distribution of nodes makes it difficult to distribute the hash value domain evenly. As can be seen from above, the data stored by the three nodes is uneven.
- After dynamically adding nodes, it is difficult to continue ensuring uniformity even if the original distribution was uniform.
- One serious drawback caused by adding or removing nodes is:
- When a node becomes abnormal, all its load will be transferred to an adjacent node.
- When a new node joins, it can only share the load with one adjacent node.
Virtual Nodes
Rob Pike said: “In computer science, there are no problems that cannot be solved with another layer of indirection.” Consistent hashing follows this principle as well.
If the three nodes are imbalanced, we can virtualize them into N virtual nodes: A[a1,a2….a1024]. Then, we map them onto a hash ring in this way.
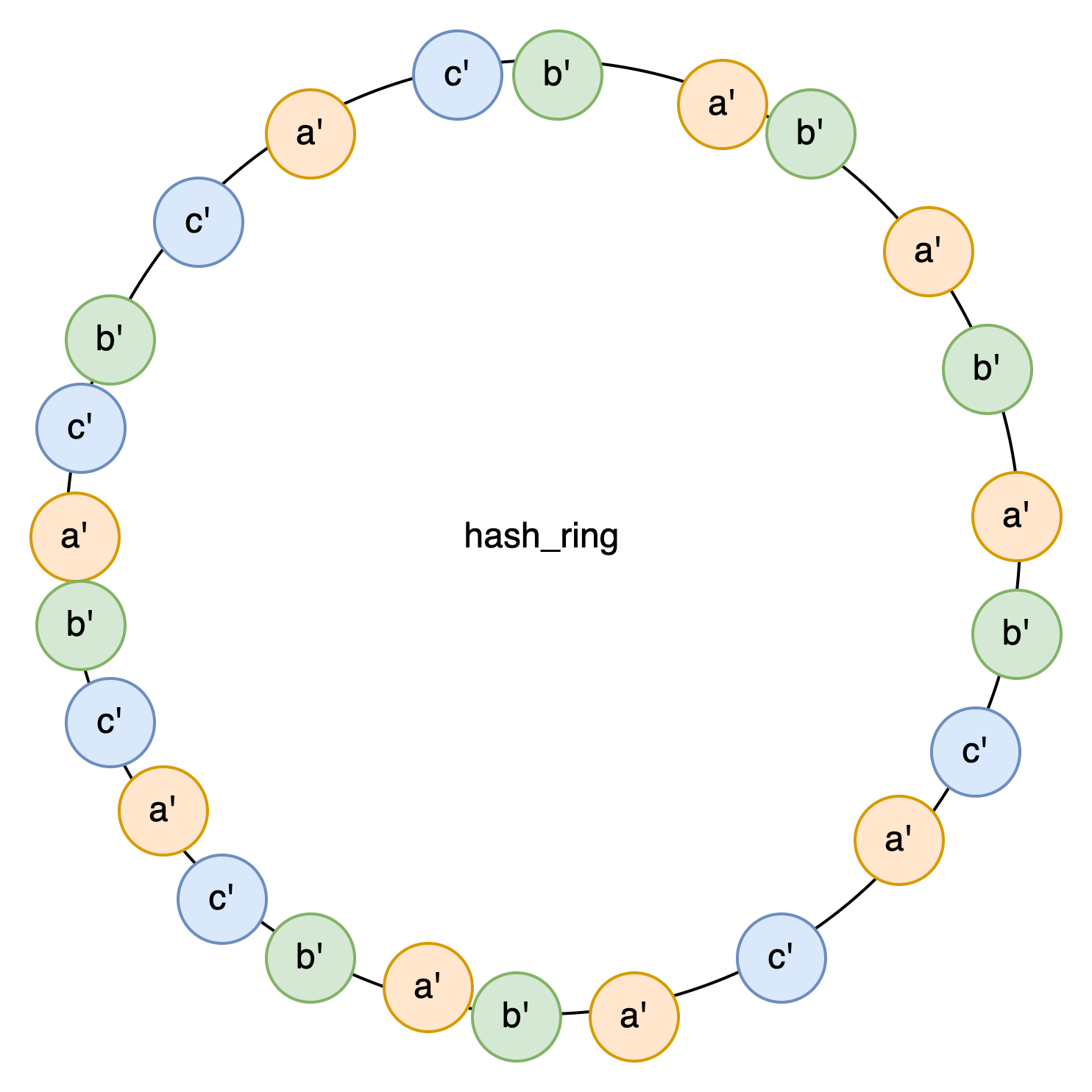
Each virtual node has a corresponding hash range. It is responsible for a segment of keys and then reads and writes data based on the virtual node’s name to find the corresponding physical node.
The above three problems are perfectly solved with the introduction of virtual nodes.
- As long as we have enough virtual nodes, the data of each node can be balanced (⚠️: this comes at a cost in engineering).
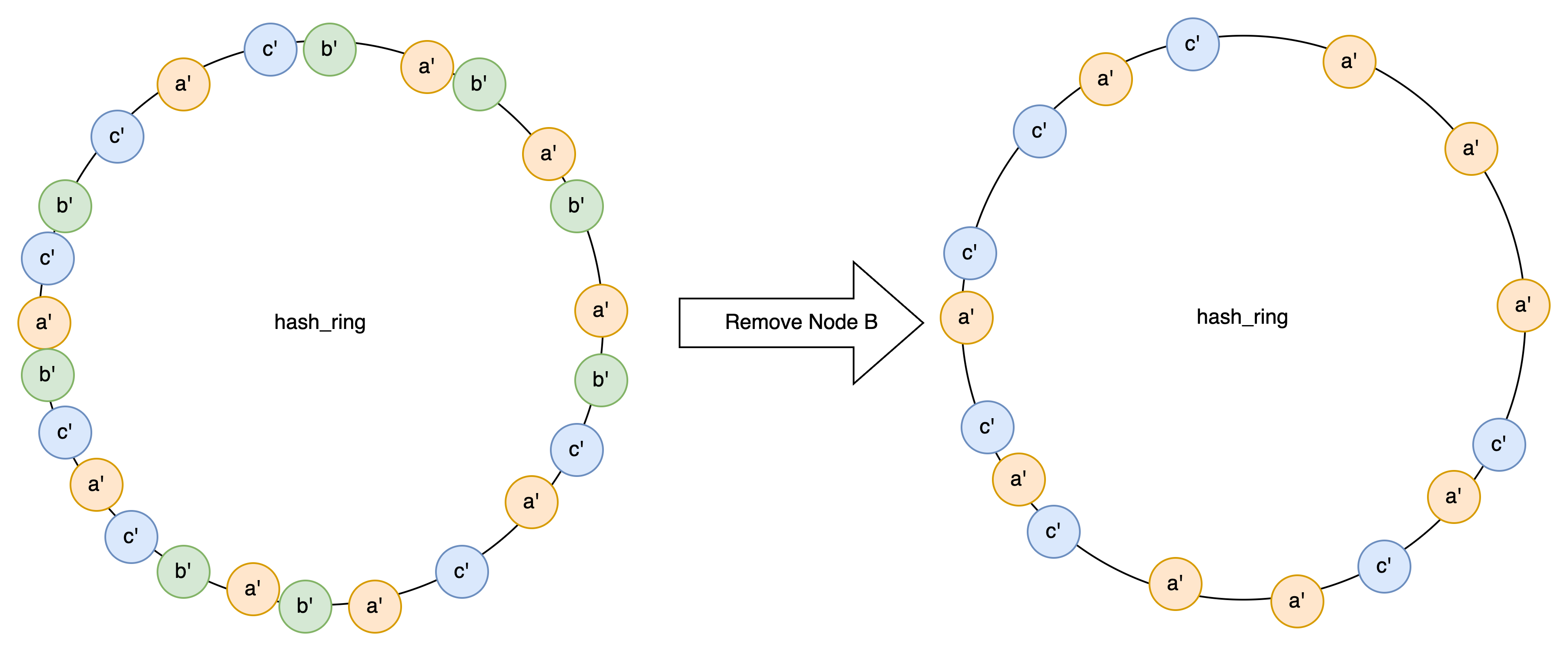
- If a node goes down, its data will be evenly distributed among all nodes in the cluster. Similarly, newly added nodes can also handle the load of all nodes.
Go language implementation
First, define a hash_ring and use crc32.ChecksumIEEE as the default hash function.
|
|
Let’s take a look at how to add a physics node:
|
|
For each added node, the corresponding number of virtual nodes must be created, and it is necessary to ensure that the virtual nodes are ordered (so that they can be searched).
Similarly, when removing, virtual nodes also need to be deleted.
|
|
When querying, we first locate the corresponding virtual node, and then find the corresponding physical node based on the virtual node.
|
|
Finally, let’s take a look at how the business uses this hash_ring
|
|
In this way, we have achieved the simplest key-value storage based on consistent hashing. Isn’t it very simple? But it supports the operation of our entire network world.
- Long Time Link
- If you find my blog helpful, please subscribe to me via RSS
- Or follow me on X
- If you have a Medium account, follow me there. My articles will be published there as soon as possible.